来源参考官方文档: https://neo4j.com/docs/getting-started/current/cypher-intro/
语法 https://neo4j.com/docs/cypher-manual/current/syntax/
图数据库

节点是图形中的实体。
- 可以使用标签标记节点,以表示它们在您的域中的不同角色。(例如Person)
- 节点可以保存任意数量的键值对或属性。(例如name)
- 节点标签还可以将元数据(如索引或约束信息)附加到某些节点。
关系提供两个节点实体(例如,Person-Person )之间的定向、命名连接
- 关系始终具有方向、类型、开始节点和结束节点,并且可以具有属性,就像节点一样。
- 节点可以具有任意数量或类型的关系,而不会牺牲性能。
- 尽管关系总是有方向性的,但它们可以在任何方向上有效地导航。
一 模式
Neo4j的属性图由节点和关系组成,其中任何一个都可能具有属性。节点表示实体,例如概念、事件、地点和事物。关系连接成对的节点。
然而,节点和关系可以被视为低级构建块。属性图的真正优势在于它能够编码连接节点和关系的模式。单个节点或关系通常编码很少的信息,但节点和关系的模式可以编码任意复杂的思想。
Neo4j的查询语言Cypher强烈基于模式。具体来说,模式用于匹配所需的图形结构。一旦找到或创建了匹配结构,Neo4j就可以使用它进行进一步处理。
一个简单的模式只有一个关系,它连接一对节点(或者偶尔连接一个节点到自身)。例如, a Person a City or a City is a Country.LIVES_IN PART_OF
使用多种关系的复杂模式可以表达任意复杂的概念,并支持各种有趣的用例。例如,我们可能希望匹配Person为Country的实例。以下Cypher代码将两个简单的模式组合成一个稍微复杂的模式,以执行match:LIVES_IN``
(:Person) -[:LIVES_IN]-> (:City) -[:PART_OF]-> (:Country) |
删除所有数据
match (n) detach delete n |
节点语法
Cypher使用一对括号来表示节点:。这让人联想到带有圆角端帽的圆形或矩形。以下是一些节点的示例,提供了不同类型和数量的详细信息:()
() |
最简单的形式,表示一个匿名的、没有特征的节点。如果我们想在其他地方引用节点,我们可以添加一个变量.一个变量被限制为一个语句,它在另一种说法中可能有不同或没有意义.
该模式声明节点的标签。这允许我们限制模式,使其不匹配(例如)具有此:Movie Actor中节点的结构
节点的属性表示为键值对列表,包含在一对大括号中,属性可用于存储信息和/或限制模式
1.1 关系语法
Cypher使用一对破折号()表示无方向关系。定向关系的一端有一个箭头(,)。括号表达式()可用于添加详细信息。这可能包括变量、属性和类型信息:—<——>[…]
--> |
关系括号对中的语法和语义与节点括号之间的语法和语法非常相似。可以定义一个变量,以便在语句的其他地方使用。关系的类型类似于节点的标签。属性完全等同于节点属性。
1.2 模式语法
结合节点和关系的语法,我们可以表达模式。以下可能是此域中的简单模式(或事实):
(keanu:Person:Actor {name: 'Keanu Reeves'})-[role:ACTED_IN {roles: ['Neo']}]->(matrix:Movie {title: 'The Matrix'}) |
与节点标签等效,模式声明关系的关系类型。变量可以在语句的其他地方用于引用关系。
与节点属性一样,关系属性表示为一对大括号内的键/值对列表,例如在本例中我们为使用了数组属性,允许指定多个角色。属性可用于存储信息和/或限制模式{roles: ['Neo']}角色
1.3 模式变量
为了增加模块性并减少重复,Cypher允许将模式分配给变量。这允许检查匹配路径,在其他表达式中使用等。
acted_in = (:Person)-[:ACTED_IN]->(:Movie) |
该变量将包含两个节点以及找到或创建的每个路径的连接关系。有许多函数可以访问路径的详细信息
二 模式实践
2.1 创建和返回数据
要添加数据,只需使用您已经知道的模式。通过提供模式,您可以指定要将哪些图形结构、标签和属性作为图形的一部分。
显然,最简单的子句叫做CREATE。它创建您指定的模式。
对于到目前为止已查看的模式,可能如下所示:
CREATE (:Movie {title: 'The Matrix', released: 1997}) |
如果还希望返回创建的数据,可以添加return子句,该子句引用已分配给模式元素的变量。Cypher中的RETURN关键字指定您可能希望从Cypher查询返回的值或结果。您可以告诉Cypher在查询结果中返回节点、关系、节点和关系属性或模式。执行写入过程时不需要RETURN,但读取时需要RETURN.
CREATE (p:Person {name: 'Keanu Reeves', born: 1964}) |
如果要创建多个元素,可以使用逗号分隔元素或使用多个create语句。
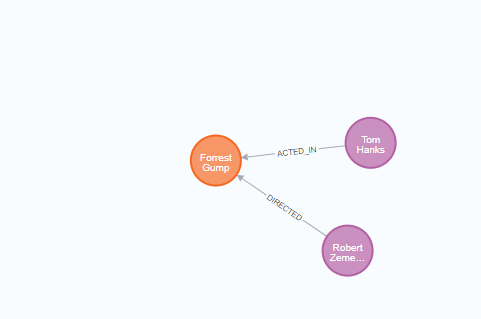
CREATE (a:Person {name: 'Tom Hanks', born: 1956})-[r:ACTED_IN {roles: ['Forrest']}]->(m:Movie {title: 'Forrest Gump', released: 1994}) |
生成的数据如下
2.2 匹配模式
匹配模式是MATCH语句的一项任务。您传递到目前为止用于MATCH的相同类型的模式来描述您正在查找的内容。它类似于按示例查询,只是您的示例还包括结构。要恢复节点、关系、属性或模式,需要在MATCH子句中为要返回的数据指定变量。
MATCH语句搜索您指定的模式,并在每个成功的模式匹配中返回一行。
要查找到目前为止创建的数据,可以开始查找标有“电影”标签的所有节点。
MATCH (m:Movie) |
查询结果为

您还可以查找特定的人
MATCH (p:Person {name: 'Keanu Reeves'}) |
查询结果为

请注意,您只提供足够的信息来查找节点,而不是所有属性都是必需的。在大多数情况下,您需要查找SSN、ISBN、电子邮件、登录名、地理位置或产品代码等关键属性。
你还可以找到更多有趣的联系,比如汤姆·汉克斯出演的电影标题和他扮演的角色。
MATCH (p:Person {name: 'Tom Hanks'})-[r:ACTED_IN]->(m:Movie) |
查询结果

在本例中,您只返回了感兴趣的节点和关系的属性。您可以通过点符号在任何地方访问它们
2.2.1 Cypher 示例
2.2.1.1 基本示例
让我们看看使用MATCH和RETURN关键字的一些示例。后面的每个示例都比前面的示例更复杂。最后两个例子从解释我们试图实现的目标开始。如果单击每个Cypher代码段下面的运行查询按钮,您可以看到图形或表格格式的结果。
示例1:在图中查找标记的Person节点。请注意,如果要在RETURN子句中检索节点,则必须为Person节点使用像p这样的变量。
MATCH (p:Person) |
示例2:在图中查找名为“Tom Hanks”的Person节点。请记住,您可以根据需要命名变量,只要稍后引用相同的名称即可。
MATCH (tom:Person {name: 'Tom Hanks'}) |
示例3:查找汤姆·汉克斯执导的电影。
解释:首先,您应该找到Tom Hanks的Person节点,然后找到他连接到的Movie节点。要做到这一点,您必须遵循从Tom Hanks Person节点到Movie节点的DIRECTED关系。您还指定了Movie的标签,以便查询仅查找具有该标签的节点。由于您只关心在该查询中返回电影,因此需要为该节点提供一个变量(movie),但不需要为Person节点或DIRECTED关系提供变量。
MATCH (:Person {name: 'Tom Hanks'})-[:DIRECTED]->(movie:Movie) |
示例4:查找汤姆·汉克斯执导的电影,但这次只返回电影的标题。
说明:此查询与上一个类似。示例3返回了整个Movie节点及其所有属性。对于这个例子,你仍然需要找到汤姆的电影,但现在你只关心它们的标题。应该使用语法变量访问节点的title属性。属性返回名称值。
MATCH (:Person {name: 'Tom Hanks'})-[:DIRECTED]->(movie:Movie) |
2.2.2 别名返回值
并非所有属性都像电影一样简单。标题。由于属性长度、多词描述、开发人员术语和其他快捷方式,一些属性的名称很差。这些命名约定很难理解,特别是当它们最终出现在报表和其他面向用户的界面上时。
MATCH (tom:Person {name:'Tom Hanks'})-[rel:DIRECTED]-(movie:Movie) |
与SQL一样,您可以使用AS关键字重命名返回结果,并使用更干净的名称为属性别名。
MATCH (tom:Person {name:'Tom Hanks'})-[rel:DIRECTED]-(movie:Movie) |
您可以通过在别名(movie.released AS Year released)前后使用反引号字符来指定具有空格的返回别名。如果没有包含空格的别名,则不需要使用反引号。
2.2.3 连接结构
要使用新信息扩展图形,首先要匹配现有的连接点,然后使用关系将新创建的节点附加到它们。将《云图》作为汤姆·汉克斯的新电影可以这样实现:
MATCH (p:Person {name: 'Tom Hanks'}) |
以下是数据库中的结构:

重要的是要记住,您可以将变量分配给节点和关系,并在以后使用它们,无论它们是创建的还是匹配的
可以在一个CREATE子句中附加节点和关系。但为了可读性,将它们分开是有帮助的。
MATCH和CREATE组合的一个棘手的方面是,每个匹配的模式得到一行。这会导致后续的CREATE语句对每行执行一次。在很多情况下,这就是你想要的。如果不是这样,请将CREATE语句移到MATCH之前,或者使用稍后讨论的方法更改查询的基数,或者使用下一个子句的get或CREATE语义:MERGE。
2.2.4 正在完成模式
每当您从外部系统获取数据或不确定图形中是否已经存在某些信息时,您都希望能够表示可重复的(幂等)更新操作。在Cypher MERGE子句中具有此功能。它就像MATCH或CREATE的组合,在创建数据之前检查数据的存在。使用MERGE,可以定义要查找或创建的模式。通常,与MATCH一样,您只希望在核心模式中包含要查找的键属性。MERGE允许您提供要在CREATE上设置的其他属性。
如果您不知道您的图形是否已包含Cloud Atlas,则可以再次合并它。
MERGE (m:Movie {title: 'Cloud Atlas'}) |
在这两种情况下都会得到结果:要么是图形中已经存在的数据(可能不止一行),要么是一个新创建的Movie节点。
MERGE子句中没有任何先前分配的变量,它要么匹配完整模式,要么创建完整模式。它从不在模式中产生匹配和创建的部分混合。要实现部分匹配/创建,请确保对不受影响的部分使用已定义的变量。
因此,最重要的是,MERGE确保您不能创建重复的信息或结构,但它需要首先检查现有匹配项的成本。特别是在大型图上,扫描一大组标记节点以查找特定属性可能会花费高昂的成本。您可以通过创建支持索引或约束来缓解其中的一些问题,这将在接下来的章节中讨论。但它仍然不是免费的,所以无论何时,如果您确定不创建重复数据,请使用create over MERGE。
MERGE还可以断言,一段关系只创建一次。为了实现这一点,您必须从先前的模式匹配中传入两个节点。
MATCH (m:Movie {title: 'Cloud Atlas'}) |

如果关系的方向是任意的,可以省略箭头。MERGE检查任一方向的关系,如果没有匹配的关系,则创建新的定向关系。
如果您选择只传入前一个子句中的一个节点,MERGE提供了一个有趣的功能。它只在给定模式的所提供节点的直接邻域内匹配,如果找不到该模式,则创建它。这对于创建例如树结构非常方便。
CREATE (y:Year {year: 2014}) |
这是创建的图形结构:

这里没有两个Month节点的全局搜索;它们仅在2014年节点的上下文中搜索。
2.3 查询数据
参见官方文档 https://neo4j.com/docs/getting-started/current/cypher-intro/results/
2.3.1 示例数据
在本节中,使用了两个示例数据集。第一个图形基于电影数据库。以下代码块帮助您创建用于探索Cypher查询的数据:
CREATE (matrix:Movie {title: 'The Matrix', released: 1997}) |
数据如下:

2.3.2 过滤数据
到目前为止,您已经在图表中匹配了模式,并始终返回找到的所有结果。现在,让我们看看过滤结果的选项,并只返回您感兴趣的数据子集。这些筛选条件使用WHERE子句表示。该子句允许使用任意数量的布尔表达式、谓词以及AND、OR、XOR和NOT。最简单的谓词是比较;特别是相等。
MATCH (m:Movie) |
Rows: 1 |
上面使用WHERE子句的查询等效于此查询,该查询包含模式匹配中的条件:
MATCH (m:Movie {title: 'The Matrix'}) |
Cypher的设计是灵活的,因此编写查询的方式通常不止一种。
其他选项包括数值比较、匹配正则表达式以及检查列表中是否存在值。
以下示例中的WHERE子句包括正则表达式匹配、大于比较和测试列表中是否存在值:
MATCH (p:Person)-[r:ACTED_IN]->(m:Movie) |
Rows: 1 |
高级方面是模式可以用作谓词。当MATCH扩展匹配的模式的数量和形状时,模式谓词限制当前结果集。它只允许满足指定模式的路径通过。正如您所期望的,NOT的使用只允许不满足指定模式的路径通过。
MATCH (p:Person)-[:ACTED_IN]->(m) |
+----------------------------------------------------------------------------------------------+ |
在这里,你可以找到演员,因为他们有ACTED_IN关系,但可以跳过那些曾经执导过任何电影的演员。
还有更高级的过滤方法,例如列表谓词,这将在本节稍后讨论。
2.3.3 查询值范围
经常有查询需要查找特定范围内的数据。日期或数字范围可用于检查特定时间线内的事件、年龄值或其他用途。
该标准的语法与用于检查值范围的SQL和其他编程语言逻辑结构非常相似。
以下数据集用于演示这些情况下的Cypher查询。

想象一下,你想知道谁拥有三到七年的经验。下面的代码块显示了这种情况下的Cypher查询。
MATCH (p:Person) |

2.3.4 测试属性是否存在
只有在节点或关系上存在属性时,您才会感兴趣。例如,您可能希望检查系统中哪些客户拥有Twitter句柄,以便显示相关内容。或者您可以检查是否所有员工都有开始日期属性,以验证哪些实体可能需要更新。
记住:在Neo4j中,只有当属性具有值时,它才存在(存储)。未存储空属性。这样可以确保只为节点和关系保留有价值的必要信息。
要在Neo4j v5中编写这种类型的存在性检查,您需要使用ISNOTNULL谓词来仅包含存在属性的节点或关系。
//Query1: find all users who have a birthdate property |
Query1 results:
Rows: 9 |
Query2 results:

2.3.5 模糊搜索
某些场景需要与字符串中的部分值或大类别匹配的查询语法。要进行这种查询,您需要一些字符串匹配和搜索的灵活性和选项。无论您正在寻找一个以某个值开头、结尾或包含某个值的字符串,Cypher都能高效轻松地处理它。
Cypher中有几个关键字与WHERE子句一起用于测试字符串属性值。STARTS WITH关键字允许您检查以指定字符串开头的属性的值。使用CONTAINS关键字,可以检查指定的字符串是否是属性值的一部分。ENDS_WITH关键字检查指定值的属性字符串的结尾。
下面的Cypher块中提供了每个示例。
//check if a property starts with 'M' |
您还可以使用正则表达式来测试字符串的值。例如,您可以查找共享名字的所有Person节点,也可以查找具有特定部门代码的所有类。
MATCH (p:Person) |
Rows: 2 |
就像在SQL和其他语言中一样,您可以检查属性值是否是列表中的值。IN关键字允许您指定一个值数组,并根据列表中的每个值验证属性的内容。
MATCH (p:Person) |
Rows: 3 |
2.3.6 过滤模式
图的独特之处在于它关注关系。正如可以根据节点标签或属性过滤查询一样,也可以根据关系或模式过滤结果。这允许您测试一个模式是否也具有某种关系,或者是否存在另一个模式。
//Query1: find which people are friends of someone who works for Neo4j |
查询结果分别如下:

Rows: 1 |
2.3.7 可选模式
在某些情况下,您可能希望从模式中检索结果,即使它们与整个模式或所有条件不匹配。这就是SQL中的外部联接的作用。在Cypher中,您可以使用OPTIONAL MATCH模式来尝试匹配它,但如果找不到结果,这些行将为这些值返回null。
通过查询姓名以特定字母开头的人以及可能在公司工作的人,您可以看到Cypher中的情况。
//Find all people whose name starts with J and who may work for a company. |
查询结果如下:
+--------------------------------+ |
请注意,返回Joe是因为他的名字以字母“J”开头,但他的公司名称为空。这是因为他与COMPANY节点没有WORKS_FOR关系。由于使用了OPTIONAL MATCH,他的Person节点仍然从第一个匹配中返回,但第二个匹配未找到,因此返回null。
若要查看差异,请尝试在第二个匹配前面不使用OPTIONAL的情况下运行查询。你可以看到乔的那一行不再被退回。这是因为Cypher使用AND匹配项读取语句,因此此人必须符合第一个条件(名称以“J”开头)和第二个条件(此人为公司工作)。
2.3.8 更复杂的模式
即使在此时,您也能够处理许多简单的图形查询。但是,当你想将你的模式扩展到一段单一的关系时,会发生什么呢?如果你想知道除了詹妮弗之外还有谁喜欢图形呢?
我们通过简单地添加到第一个模式或匹配其他模式来处理这个功能和其他许多功能。让我们来看几个例子。
//Query1: find who likes graphs besides Jennifer |
查询结果如下:
Query1 results:
Rows: 3 |
Query2 results:
Rows: 2 |
注意,在第二个查询中,在第一个MATCH行之后使用逗号,并添加另一个模式以匹配下一行。这允许您将模式链接在一起,类似于使用上面的WHERE exists(<pattern>)语法。使用此结构,您可以添加多个不同的模式并将它们链接在一起,从而允许您使用特定的模式遍历图形的各个部分。
2.4 返回结果
2.4.1 基本使用
到目前为止,您已经通过其变量直接返回了节点、关系和路径。但是,RETURN子句可以返回任意数量的表达式。但是Cypher中的表达是什么?
最简单的表达式是文字值。文字值的示例有numbers, strings, arrays (for example: [1,2,3]) 和 maps (for example: {name: 'Tom Hanks', born:1964, movies: ['Forrest Gump', ...], count: 13}).。可以使用点语法访问任何节点、关系或映射的单独属性,例如:n.name。可以使用下标检索数组的单个元素或切片,例如:names[0]和movies[1..-1]。每个函数求值,例如:length(array), toInteger('12'), substring('2014-07-01', 0, 4) and coalesce(p.nickname, 'n/a')也是一个表达式。
WHERE子句中使用的谓词算作布尔表达式。
可以组合和连接简单表达式以形成更复杂的表达式。
默认情况下,表达式本身用作列的标签,在许多情况下,您希望使用表达式as alias以更易于理解的名称对其进行别名。随后可以使用别名来引用该列。
MATCH (p:Person) |
查询结果如下
+-------------------------------------------------------------------------------------------------------------------------------------------------+ |
如果希望仅显示唯一结果,可以在RETURN之后使用DISTINCT关键字:
MATCH (n) |
结果如下:
+------------+ |
2.4.2 返回唯一结果
您可以使用Cypher中的DISTINCT关键字返回唯一结果。由于节点的多个路径或满足多个条件的节点,某些查询可能会返回重复的结果。这种冗余可能会使结果混乱,并使筛选一长串列表很难找到您需要的内容。
要修剪重复的实体,可以使用DISTINCT关键字。
//Query: find people who have a twitter or like graphs or query languages |
结果如下
Rows: 3 |
对于前面的查询,用例是您正在启动一个新的Twitter帐户,以获取有关Cypher的提示和技巧,并且您希望通知拥有Twitter帐户并且喜欢图形或查询语言的用户。查询的前两行查找具有Twitter句柄的Person节点。然后,您使用WITH将这些用户传递到下一个MATCH,在那里您可以发现用户是否喜欢图形或查询语言。请注意,在不使用DISTINCT关键字的情况下运行此语句会导致“Melissa”显示两次。这是因为她喜欢图形,也喜欢查询语言。使用DISTINCT时,仅检索唯一用户。
2.4.3 限制结果数量
有时,您需要一个采样集,或者一次只需要提取这么多结果来更新或处理。LIMIT关键字接受查询的输出,并根据指定的数量限制返回的卷。
例如,你可以在我们的图表中找到每个人的朋友数。如果该图是数千或数百万个节点和关系,则返回的结果数量将是巨大的。如果你只关心朋友最多的前三个人呢?让我们为此编写一个查询!
//Query: find the top 3 people who have the most friends |
结果如下
Rows: 3 |
该查询提取人员及其连接的朋友,并返回其朋友的姓名和计数。您可以运行这么多的查询,并返回一个杂乱的姓名和好友数量列表,但您可能希望根据每个人的好友数量来排序列表,从顶部的最大数字开始(DESC)。您也可以运行大量的查询来查看好友并按顺序计数,但在上面的示例中,已经从图表中提取了好友最多的前三名。LIMIT从排序列表中提取顶部结果。
尝试通过删除
ORDER BY和LIMIT行来混合查询,然后分别添加每一行。注意,只有删除ORDER BY行才能从列表中提取开始的三个值,从而获得返回结果的随机抽样。
2.5 聚合信息
在许多情况下,我们希望聚合或分组遍历图中的模式时遇到的数据。在Cypher中,在计算最终结果时,RETURN子句中发生聚合。支持许多常见的聚合函数,例如count、sum、avg、min和max,但还有几个。
计算电影数据库中的人数可以通过以下方式实现:
MATCH (:Person) |
查询结果如下
Rows: 1 |
请注意,聚合期间跳过NULL值。对于仅聚合唯一值,请使用DISTINCT,例如:count(DISTINCT role)。
聚合在Cypher中隐式工作。指定要聚合的结果列。Cypher使用所有非聚合列作为分组键。聚合会影响排序或后续查询部分中哪些数据仍然可见。下面的陈述说明了演员和导演合作的频率:
MATCH (actor:Person)-[:ACTED_IN]->(movie:Movie)<-[:DIRECTED]-(director:Person) |
查询结果如下
Rows: 1 |
Cypher中的count()函数允许您计算返回的实体、关系或结果的出现次数。
有两种不同的方法可以计算查询的返回结果。
- 第一种方法是使用
count(n)计算n的出现次数,并且不包括空值。可以在圆括号内指定节点、关系或属性,以便Cypher计数。 - 第二种计算结果的方法是使用
count(*),它计算返回的结果行数(包括具有空值的行数)。
在数据集中,一些Person节点有Twitter句柄,但其他节点没有。如果您运行下面的第一个示例查询,您将看到twitter属性的值为四人,其他五人为空。第二个和第三个查询显示了如何使用不同的计数选项。
//Query1: see the list of Twitter handle values for Person nodes |
查询结果
Rows: 9
+--------------+
| p.twitter |
+--------------+
| '@jennifer' |
| '@melissa' |
| null |
| '@mark' |
| '@dan' |
| null |
| null |
| null |
| null |
+--------------+
Rows: 9 |
//Query2: count of the non-null `twitter` property of the Person nodes |
查询结果
Rows: 1 |
//Query3: count on the Person nodes |
查询结果
Rows: 1 |
2.6 Collecting aggregation
一个非常有用的聚合函数是collect(expression),它返回表达式返回的值的单个聚合列表。这在许多情况下非常有用,因为聚合时不会丢失任何细节信息。
collect()非常适合于检索典型的父子结构,其中每行返回一个核心实体(父实体、根实体或头实体),并将其所有从属信息保存在使用collect(创建的关联列表中。这意味着不需要为每个子行重复父信息,也不需要运行n+1语句来单独检索父行及其子行。
以下语句可用于检索数据库中每部电影的演员阵容:
MATCH (m:Movie)<-[:ACTED_IN]-(a:Person) |
查询结果如下
Rows: 2 |
collect()创建的列表可以从使用Cypher结果的客户端使用,也可以直接在带有任何列表函数或谓词的语句中使用。
2.7 循环列表值
如果您有一个要检查或分离值的列表,Cypher提供UNWIND子句。这与collect()相反,并将列表分隔成单独行上的单个值。
UNWIND通常用于在导入数据时循环JSON和XML对象,以及日常数组和其他类型的列表。让我们看几个例子,我们假设某人喜欢的技术也意味着他们对每一项都有一定的经验。如果您对招聘熟悉图形或查询语言的人员感兴趣,可以编写以下查询来查找要面试的人员。
//Query1: for a list of techRequirements, look for people who have each skill |
查询结果如下
Rows: 2 |
//Query2: for numbers in a list, find candidates who have that many years of experience |
查询结果
Rows: 4 |
2.8 排序和分页
在使用count(x)进行聚合后,通常进行排序和分页。
使用ORDER BY expression [ASC|DESC]子句进行排序。表达式可以是任何表达式,只要它可以根据返回的信息计算。
例如,如果您返回某人。name您仍然可以按个人订购。年龄,因为两者都可以从个人参考中访问。你不能按未退回的东西点菜。这对于聚合和DISTINCT返回值尤其重要,因为两者都会删除聚合数据的可见性。
分页使用SKIP{offset}和LIMIT{count}子句完成。
一种常见的模式是聚合计数(分数或频率),按其排序,然后只返回前n个条目。
例如,要找到最高产的演员,你可以做到:
MATCH (a:Person)-[:ACTED_IN]->(m:Movie) |
结果为
Rows: 1 |
2.9 排序结果
如果您可以根据最丰富或最不丰富的经验对应聘者进行排序,我们从前面的示例中列出的潜在招聘人选可能会更有用。或者你想按年龄对我们所有的人进行排名。
ORDER BY关键字根据您指定的值按升序或降序(默认为升序)对结果进行排序。让我们使用UNWIND示例中的相同查询,看看如何订购候选人。
//Query1: for a list of techRequirements, look for people who have each skill |
结果为
Rows: 2 |
//Query2: for numbers in a list, find candidates who have that many years of experience |
结果为
Rows: 4 |
注意,在将值收集到列表中之前,第一个查询必须按人名排序。如果不首先排序(将ORDER BY放在RETURN子句之后),则将根据列表的大小而不是列表中值的第一个字母进行排序。结果还分为两种价值观:技术,然后是人。这允许您对技术进行排序,以便将所有喜欢某项技术的人列在一起。
您可以通过运行以下查询来尝试按两个值或一个值排序的区别:
第一个实例
//only sorted by person's name in alphabetical order |
第二个实例
//only sorted by technology (person names are out of order) |
第三个实例
//sorted by technology, then by person's name |
2.10 计算列表中的值
如果您有一个值列表,还可以找到该列表中的项数,或者使用size()函数计算表达式的大小。下面的示例返回找到的项目数。
//Query1: find number of items in collected list |
结果如下
Rows: 4 |
在Neo4j v5中,如果需要查找许多关系模式,请使用COUNT{}表达式。看看下面的Cypher查询示例。
//Query2: find number of friends who have other friends |
结果为
Rows: 3 |
- Neo4j Cypher Manual: WITH, UNWIND, & More
- Neo4j Cypher Manual: Aggregation
- Neo4j Cypher Manual: size()
三 数据更新
3.1 Updating data with Cypher
数据中可能已经存在节点或关系,但要修改其属性。您可以通过匹配要查找的模式并使用SET关键字添加、删除或更新属性来完成此操作。
我们继续使用以下数据集:
到目前为止,使用上面的示例数据集,您可以更新Jennifer的节点以添加她的出生日期。下一个Cypher语句显示了如何做到这一点。
- 首先,您需要找到Jennifer的现有节点。
- 接下来,使用SET创建新属性(使用语法变量.properties)并设置其值。
- 最后,您可以返回Jennifer的节点,以确保信息正确更新。
MATCH (p:Person {name: 'Jennifer'}) |
结果如下
Set Properties: 1 |
如果您想更改Jennifer的出生日期,可以使用上面的相同查询再次查找Jennifer节点,并在SET子句中输入不同的日期。
您还可以更新Jennifer与“公司”节点的WORKS_FOR关系,以包括她开始在那里工作的年份。为此,您可以使用与上述类似的语法来更新节点。
MATCH (:Person {name: 'Jennifer'})-[rel:WORKS_FOR]-(:Company {name: 'Neo4j'}) |
结果如下
Set Properties: 1 |
如果要返回上述查询的图形视图,可以向p:Person和c:Company的节点添加变量,并将返回行写成RETURN p, rel, c.
3.2 Deleting data with Cypher
另一项操作是如何删除Cypher中的数据。对于此操作,Cypher使用DELETE关键字删除节点和关系。它与用SQL等其他语言删除数据非常相似,只有一个例外。
因为Neo4j是ACID兼容的,所以如果节点仍然具有关系,则不能删除该节点。如果你能做到这一点,那么你可能会得到一个什么都没有的关系和一个不完整的图表。
3.2.1 删除关系
要删除关系,需要找到要删除的关系的开始节点和结束节点,然后使用delete关键字,如下面的代码块所示。现在让我们继续删除Jennifer和Mark之间的IS_FRIENDS_WITH关系。我们将在稍后的练习中重新添加此关系。
MATCH (j:Person {name: 'Jennifer'})-[r:IS_FRIENDS_WITH]->(m:Person {name: 'Mark'}) |
结果
+-----------------------------------------+ |
3.2.2 删除节点
要删除不具有任何关系的节点,需要找到要删除的节点,然后使用delete关键字,就像对上面的关系所做的那样。您可以暂时删除Mark的节点,稍后再将其带回。
MATCH (m:Person {name: 'Mark'}) |
结果如下
+-----------------------------------------+ |
如果您错误地创建了一个空节点,并且需要删除它,可以使用以下Cypher语句来执行此操作:
MATCH (n) |
此语句不仅删除一个节点,还删除它所具有的所有关系。要运行该语句,您应该知道节点的内部ID。
3.2.3 删除节点和关系
实际上,您可以运行一条语句同时删除节点及其关系,而不是运行最后两个查询来删除IS_FRIENDS_WITH关系和Mark的Person节点。如上所述,Neo4j是ACID兼容的,因此如果节点仍然存在关系,则不允许删除该节点。使用DETACH DELETE语法告诉Cypher删除节点具有的任何关系,以及删除节点本身。
该语句看起来像下面的代码。首先,在数据库中找到Mark的节点。然后,DETACH DELETE行删除Mark节点在删除该节点之前所具有的任何现有关系。
MATCH (m:Person {name: 'Mark'}) |
3.2.4 删除属性
您也可以删除属性,但可以使用其他几种方法来代替使用DELETE关键字。
第一个选项是对属性使用REMOVE。这会告诉Neo4j,您希望从节点中完全删除该属性,不再存储该属性。
第二个选项是使用前面的SET关键字将属性值设置为null。与其他数据库模型不同,Neo4j不存储空值。相反,它只存储对数据有意义的属性和值。这意味着您可以在图形中的各种节点和关系上拥有不同类型和数量的属性。
为了向您展示这两个选项,让我们看看每个选项的代码。
//delete property using REMOVE keyword |
结果如下:
+-----------------------------------------+ |
3.3 使用MERGE避免重复数据
前面简要提到,Cypher中有一些方法可以避免创建重复数据。其中一种方法是使用MERGE关键字。MERGE执行“选择或插入”操作,首先检查数据库中是否存在数据。如果它存在,则Cypher将按原样返回它,或对现有节点或关系进行您指定的任何更新。如果数据不存在,Cypher将使用您指定的信息创建它。
3.3.1 在节点上使用MERGE
首先,让我们看一个这样的例子,使用下面的查询将Mark添加回数据库。您可以使用MERGE来确保Cypher检查数据库中的Mark现有节点。由于您在前面的示例中删除了Mark的节点,Cypher将找不到现有的匹配项,并将创建名称属性设置为“Mark”的新节点。
MERGE (mark:Person {name: 'Mark'}) |
结果为

如果再次运行相同的语句,Cypher这次将找到一个名称属性设置为Mark的现有节点,因此它将返回匹配的节点而不做任何更改。
3.3.2 对关系使用MERGE
就像您使用MERGE在Cypher中查找或创建节点一样,您也可以执行相同的操作来查找或创建关系。让我们重新创建Mark和Jennifer之间的IS_FRIENDS_WITH关系,就像前面的示例中那样。
MATCH (j:Person {name: 'Jennifer'}) |
请注意,在我们使用MERGE查找或创建Mark的节点和Jennifer的节点之间的关系之前,这里使用MATCH查找Mark的节点。
为什么我们不使用一个语句?
MERGE查找您指定的整个模式,以查看是返回现有模式还是创建新模式。如果整个模式(节点、关系和任何指定属性)不存在,Cypher将创建它。
Cypher从不在模式中产生匹配和创建的部分混合。为了避免混合匹配和创建,您需要首先匹配模式中的任何现有元素,然后再对您可能要创建的任何元素进行合并,就像我们在上面的语句中所做的那样。

下面是导致重复的Cypher语句,仅供参考。由于数据库中不存在此模式(Jennifer IS_FRIENDS_WITH Mark),Cypher将创建新的整个模式 — 以及它们之间的关系。
//this statement will create duplicate nodes for Mark and Jennifer |
3.3.3 处理MERGE标准
也许您希望使用MERGE来确保不创建重复项,但如果创建了模式,则需要初始化某些属性,如果仅匹配,则需要更新其他属性。在这种情况下,可以将ON CREATE或ON MATCH与SET关键字一起使用来处理这些情况。
让我们看一个例子。
MERGE (m:Person {name: 'Mark'})-[r:IS_FRIENDS_WITH]-(j:Person {name:'Jennifer'}) |
- Neo4j Cypher Manual: CREATE
- Neo4j Cypher Manual: SET
- Neo4j Cypher Manual: REMOVE
- Neo4j Cypher Manual: DELETE
- Neo4j Cypher Manual: MERGE
- Neo4j Cypher Manual: ON CREATE/ON MATCH
四 编写大型报表
我们继续使用与之前相同的示例数据:
CREATE (matrix:Movie {title: 'The Matrix', released: 1997}) |
图形如下
4.1 UNION
如果要组合具有相同结果结构的两个语句的结果,可以使用UNION[ALL]。
例如,以下声明列出了演员和导演:
MATCH (actor:Person)-[r:ACTED_IN]->(movie:Movie) |
结果为
+-------------------------------------------------+ |
注意,返回的列必须在所有子子句中以相同的方式进行别名。
上面的查询相当于这个更紧凑的查询:
MATCH (actor:Person)-[r:ACTED_IN|DIRECTED]->(movie:Movie) |
4.2 WITH
在Cypher中,您可以将语句片段链接在一起,类似于在数据流管道中执行的方式。每个片段都处理上一个片段的输出,其结果可以输入下一个片段。只有WITH子句中声明的列在后续查询部分中可用。
WITH子句用于组合各个部分,并声明哪些数据从一个流向另一个。WITH类似于RETURN子句。不同之处在于WITH子句不完成查询,而是为下一部分准备输入。表达式、聚合、排序和分页的使用方式与RETURN子句相同。唯一的区别是所有列都必须具有别名。
在下面的示例中,收集某人出现的电影,然后过滤掉仅出现在一部电影中的电影。
MATCH (person:Person)-[:ACTED_IN]->(m:Movie) |
结果为
+-------------------------------------------------------------+ |
使用WITH子句,可以将值从查询的一个部分传递到另一个部分。这允许您在查询中执行一些中间计算或操作以供以后使用。
以下示例基于此数据集:
必须在WITH子句中指定以后要使用的变量。只有这些变量被传递到查询的下一部分。使用此功能有多种方式(例如计数、收集、过滤、限制结果)。
//Query1: find and list the technologies people like |
结果为
Rows: 9 |
实例2
//Query2: find number of friends who have other friends |
结果为
Rows: 3 |
在第一个查询中,将传递人名和收集的技术类型列表。因此,RETURN子句中只能引用这些项。关系(r)和个人出生日期都不能使用,因为这些值没有传递。
在第二个查询中,只能引用p及其任何属性(名称、出生日期、年经验、推特)、朋友的集合(作为一个整体,而不是每个值)和朋友的朋友数。由于这些值是在WITH子句中传递的,因此可以在WHERE或RETURN子句中使用这些值。
WITH要求传递的所有值都有一个变量(如果它们还没有)。在MATCH子句中,Person节点被赋予了一个变量(p),因此不需要在那里分配任何变量。
WITH对于在查询之前设置参数也非常有用。在导入数据时,通常用于参数键、url字符串和其他查询变量。
//Find people with 2-6 years of experience |
四 子查询
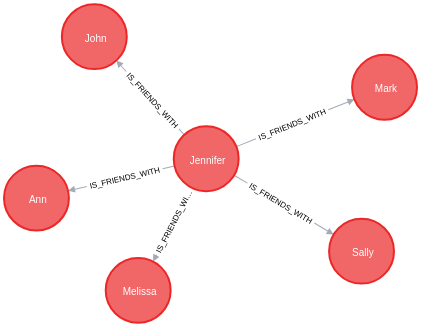
我们的所有示例都将继续使用我们之前使用的图形示例,但包括一些更多的数据,用于我们稍后的一些查询。下面是新图表的图像。
我们添加了更多的Person节点(蓝色),他们为不同的Company节点(红色)和LIKE不同的Technology(绿色)节点工作。
简而言之,每个人也可能与其他人有多个IS_FRIENDS_WITH关系。这给了我们一个人际网络,他们为之工作的公司,以及他们喜欢的技术。

Neo4j 4.0引入了对两种不同类型子查询的支持:
- WHERE子句中的存在子查询
- 使用CALL{}语法返回子查询的结果
4.1 Existential subqueries
在获得正确结果一章的模式过滤部分,我们学习了如何基于模式进行过滤。例如,我们编写了以下查询来查找Neo4j工作人员的朋友:
MATCH (p:Person)-[r:IS_FRIENDS_WITH]->(friend:Person) |
Existential subqueries 支持更强大的模式过滤。我们使用exists{}子句,而不是在WHERE子句中使用exists函数。我们可以使用以下查询重现前面的示例:
MATCH (p:Person)-[r:IS_FRIENDS_WITH]->(friend:Person) |
我们将得到相同的结果,这很好,但到目前为止,我们所取得的一切都是相同的,代码更多!
接下来,让我们编写一个子查询,它比使用WHERE子句或exists函数所能实现的过滤功能更强大。
想象一下,我们想找到那些:
- 为名称以“公司”开头的公司工作
- 至少有一项技术是三个人或更多人喜欢的
我们不想知道这些技术是什么。我们可以尝试用以下查询来回答这个问题:
MATCH (person:Person)-[:WORKS_FOR]->(company) |
运行时会出现错误提示
Variable `t` not defined (line 4, column 25 (offset: 112)) |
我们可以找到喜欢某项技术的人,但我们无法检查至少有3个人也喜欢该技术,因为变量t不在WHERE子句的范围内。让我们将两个AND语句移动到EXISTS{}块中,生成以下查询:
MATCH (person:Person)-[:WORKS_FOR]->(company) |
运行结果为
| person | company |
|---|---|
| “Melissa” | “CompanyA” |
| “Diana” | “CompanyX” |
如果我们回想一下本指南开头的图形可视化,Ryan是唯一一个为公司工作且名称以“company”开头的人。他在这个查询中被过滤掉了,因为他唯一喜欢的技术是Python,而且没有3个人喜欢Python。
4.2 Result returning subqueries
到目前为止,我们已经学会了如何使用子查询来过滤结果,但这并不能充分说明它们的功能。我们也可以使用子查询返回结果。
假设我们想编写一个查询,查找喜欢Java或有多个朋友的人。我们希望按出生日期降序返回结果。我们可以使用UNION子句获得一些方法:
MATCH (p:Person)-[:LIKES]->(:Technology {type: "Java"}) |
结果为
| person | dob |
|---|---|
| “Jennifer” | 1988-01-01 |
| “John” | 1985-04-04 |
| “Joe” | 1988-08-08 |
我们已经找到了正确的人员,但UNION方法只允许我们按照UNION子句对结果进行排序,而不是对所有行进行排序。
我们可以尝试另一种方法,分别执行每个子查询,并使用collect函数从每个部分收集人员。有些人喜欢Java,并且有不止一个朋友,因此我们还需要使用APOC库中的函数来删除这些重复项:
// Find people who like Java |
结果为
| person | dob |
|---|---|
| “Joe” | 1988-08-08 |
| “Jennifer” | 1988-01-01 |
| “John” | 1985-04-04 |
这种方法有效,但编写起来更困难,我们必须不断地将状态的部分传递到查询的下一部分。
CALL{}子句为我们提供了两全其美:
我们可以使用UNION方法来运行单个查询并删除重复项
我们可以在之后对结果进行排序
CALL { |
结果为
| person | dob |
|---|---|
| “Joe” | 1988-08-08 |
| “Jennifer” | 1988-01-01 |
| “John” | 1985-04-04 |
我们可以进一步扩展我们的查询,以返回这些人喜欢的技术和他们拥有的朋友。以下查询显示了如何执行此操作:
CALL { |
结果为
| person | dob | technologies | friends |
|---|---|---|---|
| “Joe” | 1988-08-08 | [“Query Languages”] | [“Mark”, “Diana”] |
| “Jennifer” | 1988-01-01 | [“Graphs”, “Java”] | [“Sally”, “Mark”, “John”, “Ann”, “Melissa”] |
| “John” | 1985-04-04 | [“Java”, “Application Development”] | [“Sally”] |
我们还可以将聚合函数应用于子查询的结果。以下查询返回喜欢Java或有多个朋友的人中最年轻和最年长的人
CALL { |
结果为
| oldest | youngest |
|---|---|
| 1985-04-04 | 1988-08-08 |
五 Defining a schema
示例数据
CREATE (forrestGump:Movie {title: 'Forrest Gump', released: 1994}) |

5.1 使用索引
在图形数据库中使用索引的主要原因是找到图形遍历的起点。一旦找到了起点,遍历就依赖于图内结构来实现高性能。
可以随时添加索引。
如果数据库中有现有数据,索引将需要一段时间才能联机。
以下查询创建一个索引,以加快在数据库中按名称查找参与者的速度:
CREATE INDEX example_index_1 FOR (a:Actor) ON (a.name) |
在大多数情况下,在查询数据时不必指定索引,因为将自动使用适当的索引。
复合索引是对具有特定标签的所有节点的多个属性的索引。例如,下面的语句将在标记为Actor且同时具有名称和出生属性的所有节点上创建一个复合索引。请注意,由于具有Actor标签且名称为“Keanu Reeves”的节点没有born属性。因此,该节点不会添加到索引中。
CREATE INDEX example_index_2 FOR (a:Actor) ON (a.name, a.born) |
您可以使用SHOW INDEXES查询数据库,以了解定义了哪些索引。
SHOW INDEXES YIELD name, labelsOrTypes, properties, type |
结果如下
+----------------------------------------------------------------+ |
5.2 使用约束
此示例显示如何为具有标签Movie和属性标题的节点创建约束。约束指定title属性必须是唯一的。
添加唯一约束将在该属性上隐式添加索引。如果删除了约束,但仍然需要索引,则必须显式创建索引。
CREATE CONSTRAINT constraint_example_1 FOR (movie:Movie) REQUIRE movie.title IS UNIQUE |
可以将约束添加到已包含数据的数据库中。这要求现有数据符合正在添加的约束。
您可以查询数据库以了解使用SHOW constraints Cypher语法定义了哪些约束。
六 Dates, datetimes, and durations
6.1 Creating and updating values
让我们先创建一些具有Datetime属性的节点。我们可以通过执行以下Cypher查询来做到这一点:
UNWIND [ |
在此查询中
- 创建的属性是一个DateTime类型,等于执行查询时的日期时间。
- date属性是等于执行查询时的日期的date类型。
- readingTime是3分30秒的持续时间类型。
也许我们需要对此文章节点进行一些更改,以更新datePublished和readingTime属性。
我们决定下周而不是今天发表这篇文章,所以我们想做出改变。如果我们想使用受支持的格式创建新的日期类型,可以使用以下查询:
MATCH (article:Article {title: "Dates, Datetimes, and Durations in Neo4j"}) |
以下查询将不支持的数据格式解析为基于毫秒的时间戳,根据该时间戳创建Datetime,然后根据该Datetime创建Date:
WITH apoc.date.parse("Sun, 29 September 2019", "ms", "EEE, dd MMMM yyyy") AS ms |
我们可以使用相同的方法来更新创建的属性。我们唯一需要更改的是,我们不需要将Datetime类型转换为Date:
WITH apoc.date.parse("25 September 2019 06:29:39", "ms", "dd MMMM yyyy HH:mm:ss") AS ms |
也许我们还决定,阅读时间实际上将比我们最初想象的多一分钟。我们可以使用以下查询更新readingTime属性:
MATCH (article:Article {title: "Dates, Datetimes, and Durations in Neo4j"}) |
6.2 Formatting values
现在我们要编写一个查询来返回文章。我们可以通过执行以下查询来做到这一点:
MATCH (article:Article) |
结果为
| title | created | datePublished | readingTime |
|---|---|---|---|
| “Dates, Datetimes, and Durations in Neo4j” | 2019-09-25T06:29:39Z | 2019-09-29 | P0M0DT270S |
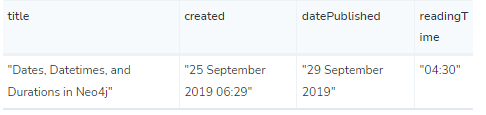
如果我们想格式化这些值,我们可以使用APOC库中的时间函数。以下查询将每个时间类型格式化为更友好的格式:
MATCH (article:Article) |
结果为
6.3 Comparing and filtering values
如果我们想根据这些时间值过滤文章呢。
让我们从查找2019年6月1日发表的文章开始。以下查询可以做到这一点:
MATCH (article:Article) |
| title | created | datePublished | readingTime |
|---|---|---|---|
| “Cypher Basics I” | 2019-06-01T18:40:32.142+01:00 | 2019-06-01 | P0M0DT135 |
如果我们想找到2019年6月发表的所有文章呢?我们可以编写以下查询来执行此操作:
MATCH (article:Article) |
| title | created | datePublished | readingTime |
|---|---|---|---|
| “Cypher Basics I” | 2019-06-01T18:40:32.142+01:00 | 2019-06-01 | P0M0DT135S |
这似乎并不正确-2019年6月2日发表的Cypher Basics II文章呢?我们在这里遇到的问题是 date({year: 2019, month:6})返回2019-06-01,因此我们只能找到2019年6月1日发布的文章。
我们需要调整我们的查询以查找2019年6月1日至2019年7月1日期间发布的文章。以下查询执行此操作:
MATCH (article:Article) |
| title | created | datePublished | readingTime |
|---|---|---|---|
| “Cypher Basics I” | 2019-06-01T18:40:32.142+01:00 | 2019-06-01 | P0M0DT135S |
| “Cypher Basics II” | 2019-06-02T10:23:32.122+01:00 | 2019-06-02 | P0M0DT150S |
如果我们希望根据存储Datetime值的已创建属性进行过滤呢?在过滤Datetime值时,我们需要采取与处理Date值相同的方法。以下查询查找2019年7月之后创建的文章:
MATCH (article:Article) |
| title | created | datePublished | readingTime |
|---|---|---|---|
| “Dates, Datetimes, and Durations in Neo4j” | 2019-09-25T06:04:39.072Z | 2019-09-25 | P0M0DT210S |
参考资料
- Neo4j Cypher Manual: WITH, UNWIND, & More
- Neo4j Cypher Manual: Aggregation
- Neo4j Cypher Manual: size()