一 基础知识
RDF(Resource Description Framework),即资源描述框架,其本质是一个数据模型(Data Model)。它提供了一个统一的标准,用于描述实体/资源。简单来说,就是表示事物的一种方法和手段。RDF是一种资源描述语言,利用当前的多种元数据标准来描述各种网络资源,形成人机可读,并可由机器自动处理的文件。
RDFS用于定义数据的结构,而不是 OWL.OWL描述了语义关系,正常的编程,例如C结构,没有被讨论,并且更接近AI研究和集合论.
RDF和RDFS
下一层是RDF - 资源描述框架.RDF为三元组定义了一些额外的结构.RDF定义的最重要的事情是一个名为”rdf:type”的谓词.这用于表示事物属于某些类型.每个人都使用rdf:type,这非常有用.
RDFS(RDF Schema)定义了一些表示主题,对象,谓词等概念的类.这意味着您可以开始创建关于事物类和关系类型的语句.在最简单的层面上,你可以说出像http://familyontology.net/1.0#hasFather这样的事情是一个人与一个人之间的关系.它还允许您在人类可读文本中描述关系或类的含义.这是一个架构.它告诉您各种类和关系的合法使用.它还用于指示类或属性是更一般类型的子类型.例如,"HumanParent"是"Person"的子类."爱"是"知识"的子类.
RDF序列化
RDF可以以多种文件格式导出.最常见的是RDF + XML,但这有一些缺点.
N3是一种非XML格式,更易于阅读,并且有一些更严格的子集(Turtle和N-Triples).
重要的是要知道RDF是一种处理三元组的方式,而不是文件格式.
XSD
XSD是一个命名空间,主要用于描述属性类型,如日期,整数等.它通常在RDF数据中看到,用于识别文字的特定类型.它也用于XML模式,这是一个略有不同的鱼.
OWL
OWL为模式添加了语义.它允许您指定更多有关属性和类的信息.它也以三元组表示.例如,它可以指示”如果A已经结婚到B”那么这意味着”B isMarriedTo A”.或者,如果” C isAncestorOf D “和” D isAncestorOf E “那么” C isAncestorOf E “.owl添加的另一个有用的东西是能够说两件事情是相同的,这对于连接不同模式中表达的数据非常有帮助.你可以说在一个模式中”sired”的关系是owl:sameAs在其他模式中”生长”.你也可以用它来说两件事情是一样的,比如维基百科上的”Elvis Presley”和BBC上的一样.这非常令人兴奋,因为这意味着您可以开始加入来自多个站点的数据(这是”关联数据”).
您还可以使用OWL来推断隐含事实,例如” C isAncestorOf E “.
1.1 RDF
1.1.1 RDF基础
1.1.1 RDF核心思想
利用IRI (Internationalized Resource Identifiers, 国际化资源标识符) 来标识事物,通过指定的属性和相应的值描述资源的性质或资源之间的关系。
IRI 和 URI,可以理解为是等价的。
- R:Resource,即资源,能唯一标识的对象源,例如:地点、人、事件、餐馆等;
- D:Description,资源的描述,包括资源属性、关系等;
- F :Framework,为资源描述提供了描述的语法和模型。
1.1.1.2 RDF的基本元素
IRI(国际化资源标识符) : 一个符合特定语法的 UINICODE 字符串
例如,DBpedia中Leonardo da Vinci的IRI:http://dbpedia.org/resource/Leonardo_da_Vinci
字面值(Literal) : 字符串+表示数据类型的 IRI
"2"^^xsd:integer[表示1是整型]
空节点 : 没有 IRI 的匿名节点
1.1.1.3 RDF资源和陈述
资源:用IRI或者Literal表示的事物。
陈述:RDF 中对资源的一个描述称为陈述 (statement),一般用 Subject-Predicate-Object(SPO) 三元组 (triple) 表示。
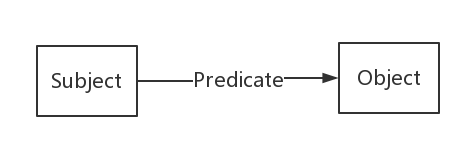
- Subject : IRI,blank node
Predicate : IRI
Object : IRI,blank node,literal
1.1.2 RDF语法
1.1.2.1 RDF 主要 元素
<rdf:RDF> 元素<rdf:RDF> 是 RDF 文档的根元素。它把 XML 文档定义为一个 RDF 文档。它也包含了对 RDF 命名空间的引用:
|
<rdf:Description> 元素<rdf:Description> 元素可通过 about 属性标识一个资源。<rdf:Description> 元素可包含描述资源的那些元素:
|
artist、country、company、price 以及 year 这些元素被定义在命名空间http://www.recshop.fake/cd# 中。此命名空间在 RDF 之外(并非 RDF 的组成部分)。RDF 仅仅定义了这个框架。而 artist、country、company、price 以及 year 这些元素必须被其他人(公司、组织或个人等)进行定义。
属性(property)来定义属性(attribute)
属性元素(property elements)也可作为属性(attributes)来被定义(取代元素):
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:cd="http://www.recshop.fake/cd#">
<rdf:Description
rdf:about="http://www.recshop.fake/cd/Empire Burlesque"
cd:artist="Bob Dylan" cd:country="USA"
cd:company="Columbia" cd:price="10.90"
cd:year="1985" />
</rdf:RDF>
属性(property)来定义属性(attribute)
属性元素(property elements)也可作为属性(attributes)来被定义(取代元素):
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:cd="http://www.recshop.fake/cd#">
<rdf:Description
rdf:about="http://www.recshop.fake/cd/Empire Burlesque">
<cd:artist rdf:resource="http://www.recshop.fake/cd/dylan" />
...
...
</rdf:Description>
</rdf:RDF>
1.1.2.2 RDF容器
RDF 容器用于描述一组事物。举个例子,把某本书的作者列在一起。
下面的 RDF 元素用于描述这些的组:<Bag>、<Seq>以及<Alt>。<rdf:Bag> 元素<rdf:Bag> 元素用于描述一个规定为无序的值的列表。<rdf:Bag> 元素可包含重复的值。
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:cd="http://www.recshop.fake/cd#">
<rdf:Description
rdf:about="http://www.recshop.fake/cd/Beatles">
<cd:artist>
<rdf:Bag>
<rdf:li>John</rdf:li>
<rdf:li>Paul</rdf:li>
<rdf:li>George</rdf:li>
<rdf:li>Ringo</rdf:li>
</rdf:Bag>
</cd:artist>
</rdf:Description>
</rdf:RDF>
<rdf:Seq> 元素<rdf:Seq> 元素用于描述一个规定为有序的值的列表(比如一个字母顺序的排序)。<rdf:Bag> 元素可包含重复的值。
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:cd="http://www.recshop.fake/cd#">
<rdf:Description
rdf:about="http://www.recshop.fake/cd/Beatles">
<cd:artist>
<rdf:Seq>
<rdf:li>George</rdf:li>
<rdf:li>John</rdf:li>
<rdf:li>Paul</rdf:li>
<rdf:li>Ringo</rdf:li>
</rdf:Seq>
</cd:artist>
</rdf:Description>
</rdf:RDF>
<rdf:Alt>元素<rdf:Alt> 元素用于一个可替换的值的列表(用户仅可选择这些值的其中之一)。
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:cd="http://www.recshop.fake/cd#">
<rdf:Descriptio
rdf:about="http://www.recshop.fake/cd/Beatles">
<cd:format>
<rdf:Alt>
<rdf:li>CD</rdf:li>
<rdf:li>Record</rdf:li>
<rdf:li>Tape</rdf:li>
</rdf:Alt>
</cd:format>
</rdf:Descriptio>
</rdf:RDF>
RDF 集合
RDF 集合用于描述仅包含指定成员的组。
正如在前面的章节所看到的,我们无法关闭一个容器。容器规定了所包含的资源为成员 - 它没有规定其他的成员是不被允许的。
RDF 集合用于描述仅包含指定成员的组。
集合是通过属性rdf:parseType="Collection"来描述的。
|
1.1.3 IRI
与URI类似,是合乎规范的字符串,属于URI的一般形式。IRI引入了 Unicode 字符来解决兼容问题。
URI,只能是英文字符,无法兼容各国文字语言。
1.1.3.1 IRI设计原则
- 具有全局作用域(必须是唯一的,不能有冲突)
- 具有自解释性
- 避免Non-normalized形式[3]
不应该出现如下情况:
- Scheme的名字中使用大写字母
- IRI语法不需要的字符编码百分比
- 显示地包含HTTP 缺省端口号(http://example.com:80/); http://example.com/ 为推荐形式
- 完全空路径 (http://example.com); http://example.com/为推荐形式
- IRI路径中包含“/./” or “/../”
- 百分比编码内的小写十六进制字母 (“%3F” is preferable over “%3f”)
- 域名为纯IP编码
- 不在Unicode规范化格式C内
1.1.3.2 RDF 扩展名和MIME 类型
RDF 文件的推荐扩展名为.rdf,然而,扩展名.XML是经常被用来兼容旧的XML解析器。
MIME 类型:application/rdf+xml。
1.1.3.3 IRI命名空间
| 命名空间前缀 | IRI命名空间 |
|---|---|
| rdf | http://www.w3.org/1999/02/22-rdf-syntax-ns# |
| rdfs | http://www.w3.org/2000/01/rdf-schema# |
| xsd | http://www.w3.org/2001/XMLSchema |
RDFS / RDF 类
| 元素 | 类 | 子类 |
|---|---|---|
| rdfs:Class | All classes | |
| rdfs:Datatype | Data types | Class |
| rdfs:Resource | All resources | Class |
| rdfs:Container | Containers | Resource |
| rdfs:Literal | Literal values (text and numbers) | Resource |
| rdf:List | Lists | Resource |
| rdf:Property | Properties | Resource |
| rdf:Statement | Statements | Resource |
| rdf:Alt | Containers of alternatives | Container |
| rdf:Bag | Unordered containers | Container |
| rdf:Seq | Ordered containers | Container |
| rdfs:ContainerMembershipProperty | Container membership properties | Property |
| rdf:XMLLiteral | XML literal values | Literal |
RDFS / RDF 属性
| 元素 | 领域 | 范围 | 描述 |
|---|---|---|---|
| rdfs:domain | Property | Class | 资源域 |
| rdfs:range | Property | Class | 资源的范围 |
| rdfs:subPropertyOf | Property | Property | 该属性是一个属性的子属性 |
| rdfs:subClassOf | Class | Class | 资源是一个类的子类 |
| rdfs:comment | Resource | Literal | 人类可读的资源描述 |
| rdfs:label | Resource | Literal | 人类可读的资源标签(名称) |
| rdfs:isDefinedBy | Resource | Resource | 资源的定义 |
| rdfs:seeAlso | Resource | Resource | 关于资源的其他信息 |
| rdfs:member | Resource | Resource | 资源的成员 |
| rdf:first | List | Resource | |
| rdf:rest | List | List | |
| rdf:subject | Statement | Resource | 一个RDF陈述的资源主体 |
| rdf:predicate | Statement | Resource | 在一个RDF陈述的资源的谓词 |
| rdf:object | Statement | Resource | 一个RDF陈述的资源客体 |
| rdf:value | Resource | Resource | value属性 |
| rdf:type | Resource | Class | 资源是一个类的实例 |
RDF 属性
| 元素 | 领域 | 范围 | 描述 |
|---|---|---|---|
| rdf:about | 定义所描述的资源 | ||
| rdf:Description | 资源描述的容器 | ||
| rdf:resource | 定义资源,以确定一个属性 | ||
| rdf:datatype | 定义一个元素的数据类型 | ||
| rdf:ID | 定义元素的ID | ||
| rdf:li | 定义列表 | ||
| rdf:_n | 定义一个节点 | ||
| rdf:nodeID | 定义元素节点的ID | ||
| rdf:parseType | 定义元素应如何解析 | ||
| rdf:RDF | 一个RDF文档的根 | ||
| xml:base | 定义了XML基础 | ||
| xml:lang | 定义元素内容的语言 | ||
| rdf:aboutEach | (删除) | ||
| rdf:aboutEachPrefix | (删除) | ||
| rdf:bagID | (删除) |
1.1.4 Literals(字面值)
- Literal是指一些基本值,比如字符串,日期,数值等。
- 为方便解析Literal,通常会关联某种数据类型。
- RDF没有自己的数据类型定义,使用XML Schema数据类型。
XML是语义网的契机,因此,rdf也使用了xml Schema中的数据类型。
| 分类(部分) | 数据类型 |
|---|---|
| Core types | xsd:string |
| xsd:boolean | |
| xsd:decimal | |
| IEEE floating-point numbers | xsd:integer |
| xsd:double | |
| xsd:float | |
| Time and date | xsd:date |
| xsd:time | |
| xsd:dateTime | |
| xsd:dateTimeStamp |
1.2 RDFS
RDF的表达能力有限,无法区分类和对象,也无法定义和描述类的关系/属性。RDF是对具体事物的描述,缺乏抽象能力,无法对同一个类别的事物进行定义和描述。RDFS是RDF的扩展,它在RDF的基础上提供了一组建模原语,用来描述类、属性以及它们之间的关系。
- Type
- Class, subClassOf
- Property, subPropertyOf
- domain, range
1.2.1 RDFs基本描述元语
rdf:type:声明一个资源是一个类的实例
<人物,rdf:type, rdfs:Class>, <姚明,rdf:type,人物> |
rdf:Property:定义属性,不分对象属性和数据属性(可以理解为关系/一条边)
<国籍, rdf:type, rdf:Property>, <专业, rdf:type, rdf:Property> |
rdfs:domain, rdfs:range:声明属性所对应的资源类和属性值类
# domain 表示:...的主语是... |
1.2.2 RDFS词汇
RDF,只定义了用于描述资源的框架,它并没有定义用哪些元数据来描述资源。即,RDF并未说明,IRI所代表资源的语义信息。为了揭示相应的语义信息,此时要借助一些词汇表(vocabulary)。 RDF Schema(RDFS)就定义了,怎样用RDF来描述词汇集。也就是说,RDFS是定义RDF词汇集的词汇集。
RDFS几个比较重要,常用的词汇:
- rdfs:Class. 用于定义类
- rdfs:domain. 用于表示该属性属于哪个类别
- rdfs:range. 用于描述该属性的取值类型
- rdfs:subClassOf. 用于描述该类的父类
- rdfs:subProperty. 用于描述该属性的父属性
1.2.3 RDF属性
定义了一些用来描述关系的元数据。与RDF类相比,有定义域和值域。例如,subClassOf(…是…的子类),定义域和值域都是Class类。
1.2.4 RDFs缺点
- 只能表达简单的语义,复杂场景下表达能力较弱;
- 无法对局部值域的属性进行定义,例如:rdfs:range定义的值域是全局性;
- 无法定义类、属性、个体之间的等价性,例如:Tim-Berns Lee == T.B.Lee;
- 无法定义不相交的两个类,例如:无法声明男人和女人是不相交的;
- 无法对属性值取值进行取值约束,例如:一门课必须有一名教师。
- 无法对属性特性进行描述,例如:属性具有传递性、对称性等。
1.2.5 RDFS实例
下面的实例演示了 RDFS 的能力的某些方面:
|
在上面的例子中,资源 “horse” 是类 “animal” 的子类。
由于一个 RDFS 类就是一个 RDF 资源,我们可以通过使用rdfs:Class 取代 rdf:Description,并去掉rdf:type 信息,来把上面的例子简写一下:
|
1.3 OWL
RDFS本质上是RDF词汇的一个扩展。后来人们发现RDFS的表达能力还是相当有限,因此提出了OWL。我们也可以把OWL当做是RDFS的一个扩展,其添加了额外的预定义词汇。
OWL,即“Web Ontology Language”,语义网技术栈的核心之一。OWL有两个主要的功能:
- 提供快速、灵活的数据建模能力。
- 高效的自动推理。
owl区分数据属性和对象属性(对象属性表示实体和实体之间的关系)。词汇owl:DatatypeProperty定义了数据属性,owl:ObjectProperty定义了对象属性。
上图中,数据属性用青色表示,对象属性由蓝色表示。
描述属性特征的词汇
owl:TransitiveProperty. 表示该属性具有传递性质。例如,我们定义“位于”是具有传递性的属性,若A位于B,B位于C,那么A肯定位于C。owl:SymmetricProperty. 表示该属性具有对称性。例如,我们定义“认识”是具有对称性的属性,若A认识B,那么B肯定认识A。owl:FunctionalProperty. 表示该属性取值的唯一性。 例如,我们定义“母亲”是具有唯一性的属性,若A的母亲是B,在其他地方我们得知A的母亲是C,那么B和C指的是同一个人。owl:inverseOf. 定义某个属性的相反关系。例如,定义“父母”的相反关系是“子女”,若A是B的父母,那么B肯定是A的子女。
本体映射词汇(Ontology Mapping)
owl:equivalentClass. 表示某个类和另一个类是相同的。owl:equivalentProperty. 表示某个属性和另一个属性是相同的。owl:sameAs. 表示两个实体是同一个实体。
1.4 RDF序列化方法
RDF序列化的方式主要有:RDF/XML,N-Triples,Turtle,RDFa,JSON-LD等几种。
- RDF/XML,顾名思义,就是用XML的格式来表示RDF数据
- N-Triples,即用多个三元组来表示RDF数据集,是最直观的表示方法。在文件中,每一行表示一个三元组,方便机器解析和处理。开放领域知识图谱DBpedia通常是用这种格式来发布数据的。
- Turtle, [‘tɝtl] 应该是使用得最多的一种RDF序列化方式了。它比RDF/XML紧凑,且可读性比N-Triples好。
- RDFa,即“The Resource Description Framework in Attributes”,是HTML5的一个扩展,在不改变任何显示效果的情况下,让网站构建者能够在页面中标记实体,像人物、地点、时间、评论等等
- JSON-LD,即“JSON for Linking Data”,用键值对的方式来存储RDF数据
文件扩展名与序列化格式对应关系如下:
| Extension | Language |
|---|---|
.ttl |
Turtle |
.nt |
N-Triples |
.nq |
N-Quads |
.trig |
TriG |
.rdf |
RDF/XML |
.owl |
RDF/XML |
.jsonld |
JSON-LD |
.trdf |
RDF Thrift |
.rt |
RDF Thrift |
.rpb |
RDF Protobuf |
.pbrdf |
RDF Protobuf |
.rj |
RDF/JSON |
.trix |
TriX |
具体参见 https://jena.apache.org/documentation/io/#formats
N-Triples
<http://somewhere/JohnSmith> <http://www.w3.org/2001/vcard-rdf/3.0#FN> "John Smith" . |
Turtle
<http://somewhere/JohnSmith> |
RDF/XML
<rdf:RDF |
JSON-LD
{ |
1.5 RDF查询语言SPARQL
SPARQL即SPARQL Protocol and RDF Query Language的递归缩写,专门用于访问和操作RDF数据,是语义网的核心技术之一。W3C的RDF数据存取小组(RDF Data Access Working Group, RDAWG)对其进行了标准化。在2008年,SPARQL 1.0成为W3C官方所推荐的标准。2013年发布了SPARQL 1.1。相对第一个版本,其支持RDF图的更新,提供更强大的查询,比如:子查询、聚合操作(像我们常用的count)等等。
由两个部分组成:协议和查询语言。
- 查询语言很好理解,就像SQL用于查询关系数据库中的数据,XQuery用于查询XML数据,SPARQL用于查询RDF数据。
- 协议是指我们可以通过HTTP协议在客户端和SPARQL服务器(SPARQL endpoint)之间传输查询和结果,这也是和其他查询语言最大的区别。
一个SPARQL查询本质上是一个带有变量的RDF图,以我们之前提到的罗纳尔多RDF数据为例:
Copy<http://www.kg.com/person/1> <http://www.kg.com/ontology/chineseName> "罗纳尔多·路易斯·纳萨里奥·德·利马"^^string. |
查询SPARQL
Copy<http://www.kg.com/person/1> <http://www.kg.com/ontology/chineseName> ?x. |
SPARQL查询是基于图匹配的思想。我们把上述的查询与RDF图进行匹配,找到符合该匹配模式的所有子图,最后得到变量的值。就上面这个例子而言,在RDF图中找到匹配的子图后,将”罗纳尔多·路易斯·纳萨里奥·德·利马”和“?x”绑定,我们就得到最后的结果。简而言之,SPARQL查询分为三个步骤:
- 构建查询图模式,表现形式就是带有变量的RDF。
- 匹配,匹配到符合指定图模式的子图。
- 绑定,将结果绑定到查询图模式对应的变量上。
二 jena 操作图谱
Jena是Apache基金会旗下的开源Java框架,用于构建Semantic Web 和 Linked Data 应用。
Apache Jena(简称Jena)是一个免费的开源Java框架,用于构建语义Web和链接数据应用程序。该框架由不同的API组成,通过API交互来处理RDF数据。jena包含TDB、Rule Reasoner、Fuseki组件。Rule Reasoner可进行简单规则推理,支持用户进行自定义推理规则;Fuseki是Jena的SPARQL服务器,将三元组变为可通过HTTP访问的SPARQL节点。jena的框架如下图:
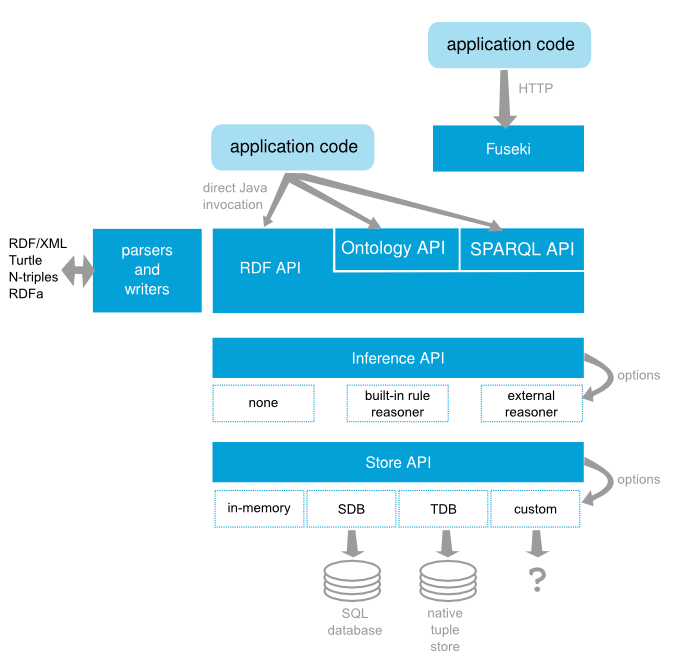
Fuseki
Apache Jena Fuseki是一个SPARQL服务器。它可以作为操作系统服务、Java web应用程序(War文件)和独立服务器运行。Fuseki提供了用于查询和更新的SPARQL 1.1协议以及SPARQL图形存储协议。Fuseki与TDB紧密集成,提供了一个健壮的事务持久存储层,并结合了Jena文本查询。
TDB
TDB是Jena的一个组件,用于RDF存储和查询。它支持全系列Jena API。TDB可用作单台计算机上的高性能RDF存储。如果想在多个应用程序之间共享TDB数据集,可以使用Fuseki组件,该组件提供了一个SPARQL服务器,该服务器可以使用TDB进行持久存储,并提供了SPARQL协议,用于通过HTTP进行查询、更新和REST更新。
Rule Reasoner
Jena推理子系统旨在允许将一系列推理引擎或推理器插入Jena。这些引擎用于派生从一些基本RDF以及任何可选的本体信息中获得RDF断言,以及与推理器关联的公理和规则。此机制的主要用途是支持使用RDFS和OWL等语言,这些语言允许从实例数据和类描述中推断出额外的事实。该机制的设计十分通用,它包括一个通用规则引擎,可用于许多RDF处理或转换任务。
依赖如下
<dependency> |
首先,三元组(triple)组成的图称之为Model,这个图里的Node可以是resources(实体)、literals(字面值)或者blank nodes。
一个三元组,在jena里称之为Statement,一个 statement 包含三部分::
- the subject :实体
- the predicate :属性
- the object : 值
三元组和URI
Subject - Predicate - Object |
这些描述了一个事实.通常,URI用于主题和谓词.该对象是另一个URI或文字,如数字或字符串.文字可以有一个类型(也是一个URI),它们也可以有一种语言.是的,这意味着三元组最多可以有5位数据!
例如,三人可能会描述查尔斯是哈里父亲的事实.
示例解释参见官方文档 https://www.w3.org/TR/vcard-rdf/
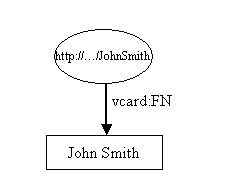
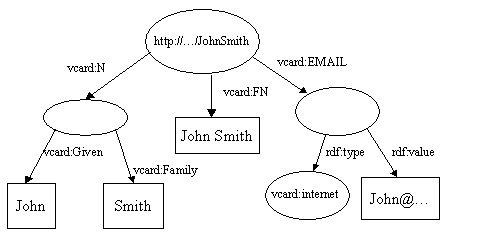
资源(resource),John Smith 被表示为一个椭圆,通过形如http://.../JohnSmith的IRI标识。
资源(Resource)具有属性(properties),在例子中我们对John Smith名片上显示的属性类型感兴趣。上图只显示了一个属性,即John Smith的全名。property 由一个标有属性名称的弧表示。property 的名称也是URI,但由于URI相当长且繁琐,因此该图以XML qname格式显示。:之前的部分称为命名空间前缀并表示命名空间。:后面的部分称为本地名称,表示该命名空间中的名称。当写为RDFXML时,属性通常以这种qname形式表示,它是在图表和字面值中表示属性的方便简写。然而严格来说属性是由URI标识的,nsprefix:localname形式是与localname连接的名称空间URI的简写。当浏览器访问属性时,不要求属性的URI解析为任何内容。
每个property 都有一个值,在本例中值是子一个字符串字面值( literal),该字面值在图中以矩形表示。
该模块具体内容参见官方文档 官方文档 https://jena.apache.org/tutorials/rdf_api.html
2.1 创建Model
Jena是一个JavaAPI,可以用来创建和操作像这样的RDF图。Jena有表示图形、资源、属性和文字的对象类。表示资源、属性和文字的接口分别称为Resource、Property和Literal。在Jena中,图形称为模型,由模型接口表示。
参见 https://github.com/apache/jena/blob/main/jena-core/src-examples/jena/examples/rdf/Tutorial01.java
// URI 定义 |
也可以使用链式API,为resource添加多个Property
参见 https://github.com/apache/jena/tree/main/jena-core/src-examples/jena/examples/rdf/Tutorial02.java
// some definitions |
2.2 遍历Model
参见 https://github.com/apache/jena/tree/main/jena-core/src-examples/jena/examples/rdf/Tutorial03.java
使用model.listStatements遍历statements,返回一个迭代器,使用hasNext判断是否还有数据,通过getSubject,getPredicate,getObject 获取三元组信息。
// list the statements in the Model |
运行结果:
http://somewhere/JohnSmith http://www.w3.org/2001/vcard-rdf/3.0#N 934770ec-dbd7-4652-a0c3-808f0243be15 . |
2.3 保存 RDF文件
参见 https://github.com/apache/jena/blob/main/jena-core/src-examples/jena/examples/rdf/Tutorial04.java
Jena有将RDF读写为XML的方法。这些可以用于将RDF模型保存到文件中,然后再将其读回。
可以使用model.write方便的把Model保存为rdf文件,write默认保存为XML格式
// now write the model in XML form to a file |
输出结果<rdf:RDF
xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'
xmlns:vcard='http://www.w3.org/2001/vcard-rdf/3.0#'
>
<rdf:Description rdf:about='http://somewhere/JohnSmith'>
<vcard:FN>John Smith</vcard:FN>
<vcard:N rdf:nodeID="A0"/>
</rdf:Description>
<rdf:Description rdf:nodeID="A0">
<vcard:Given>John</vcard:Given>
<vcard:Family>Smith</vcard:Family>
</rdf:Description>
</rdf:RDF>
RDF规范指定了如何将RDF表示为XML。RDF XML语法相当复杂。。
RDF通常嵌入<rdf:RDF元素中。如果有其他方法可以知道某些XML是RDF,那么元素是可选的,但它通常存在。RDF元素定义了文档中使用的两个名称空间。然后有一个http://somewhere/JohnSmith。如果缺少rdf:about属性,则此元素将表示一个空白节点。
这里是否有rdf:about的区别在于产生 Resource 时调用的方法是
Resource r = model.createResource(); |
还是
model.createResource(personURI) |
使用前者(无参方法)不会生成具有rdf:about的语句。
<vcard:FN>元素描述资源的属性。属性名是vcard名称空间中的“FN”。RDF通过连接名称空间前缀的URI引用和名称的本地名称部分“FN”,将其转换为URI引用。这提供了一个URI引用“http://www.w3.org/2001/vcard-rdf/3.0#FN属性的值为文字“John Smith”。
<vcard:N>元素是一种资源。在这种情况下,资源由相对URI引用表示。RDF通过将其与当前文档的基本URI连接,将其转换为绝对URI引用。
此RDF XML中存在错误;它并不完全代表我们创建的模型。模型中的空白节点已被赋予URI引用。它不再是空白的。RDF/XML语法不能表示所有RDF模型;例如,它不能表示作为两个语句对象的空白节点。我们用来编写此RDF/XML的“dumb”编写器没有尝试正确编写可以正确编写的模型子集。它为每个空白节点提供一个URI,使其不再为空白。
Jena有一个可扩展的接口,允许为RDF插入不同序列化语言的新编写器。上面的调用调用了标准的“dumb”编写器。Jena还包括一个更复杂的RDF/XML编写器,可以使用RDFDataMgr调用它。写入函数调用:
// now write the model in a pretty form |
输出如下:
<rdf:RDF |
PrettyWriter还能利用RDF/XML缩写语法的特性,更简洁地编写Model。它还可以在可能的地方保留空白节点
// now write the model in N-TRIPLES form |
此输出符合N-Triples规范
<http://somewhere/JohnSmith> <http://www.w3.org/2001/vcard-rdf/3.0#N> _:Bb0d6a82cX2D9198X2D4c0fX2Dbd49X2D3170a3726647 . |
write还提供重载版本write( OutputStream out, String lang ),lang可以为RDF/XML-ABBREV, N-TRIPLE, TURTLE (TTL) 和N3
我们来保存为常见的TURTLE:
public class JenaTest { |
结果:
<http://somewhere/JohnSmith> |
jena还提供prefix功能,我们可以指定prefix来简化turtle,下面的代码将指定prefix,并保存到文件1.rdf里:
model.setNsPrefix("vCard", "http://www.w3.org/2001/vcard-rdf/3.0#"); |
完整代码为:
public class JenaTest { |
结果:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . |
2.4 读取rdf
参见 https://github.com/apache/jena/blob/main/jena-core/src-examples/jena/examples/rdf/Tutorial05.java
Mode的read(Reader reader, String base)方法,提供 读取RDF文件的功能:
// create an empty model |
注意,read的时候,默认是读取XML,如果是其他格式,需要指定lang。
2.5 控制前缀
2.5.1 显式前缀定义
在前一节中,我们看到输出XML声明了名称空间前缀vcard,并使用该前缀缩写URI。虽然RDF只使用完整的URI,而不使用这种缩写形式,但Jena提供了通过前缀映射控制输出上使用的名称空间的方法。这里有一个简单的例子。
Model m = ModelFactory.createDefaultModel(); |
这个片段的输出是三批RDF/XML,带有三个不同的前缀映射。首先是默认值,除标准前缀外没有其他前缀:
# -- no special prefixes defined |
我们看到rdf名称空间是自动声明的,因为它是
方法setNsPrefix(String prefix,String URI)声明名称空间URI可以由前缀缩写。Jena要求前缀是合法的XML命名空间名称,并且URI以非名称字符结尾。RDF/XML编写器将这些前缀声明转换为XML命名空间声明,并在其输出中使用它们:
# -- nsA defined |
另一个名称空间仍然获得构造的名称,但nsA名称现在在属性标记中使用。前缀名不需要与Jena代码中的变量有任何关系:
# -- nsA and cat defined |
这两个前缀都用于输出,不需要生成前缀。
2.5.2 隐式前缀定义
除了调用setNsPrefix所提供的前缀声明之外,Jena还将记住在model.read()的输入中使用的前缀。
获取前面片段生成的输出,并将其粘贴到某个文件中,URL文件为:/tmp/fragment.rdf。然后运行代码:
Model m2 = ModelFactory.createDefaultModel(); |
您将看到输入的前缀保留在输出中。所有前缀都被写入,即使它们在任何地方都没有使用。如果输出中不需要前缀,可以使用removeNsPrefix(String前缀)删除前缀。
由于NTriples没有任何编写URI的快捷方式,因此它不注意输出上的前缀,也不提供任何输入上的前缀。Jena也支持表示法N3,它有短前缀名称,并在输入中记录它们,在输出中使用它们。
Jena对模型持有的前缀映射有进一步的操作,例如提取现有映射的JavaMap,或者一次添加一组映射;有关详细信息,请参阅PrefixMapping文档。
2.6 模型导航
给定资源的URI,可以使用model从模型中检索资源对象。getResource(String uri)方法定义为如果模型中存在Resource对象,则返回该对象,否则创建新对象。例如,要从文件读入的模型中检索John Smith资源:
// retrieve the John Smith vcard resource from the model |
Resource接口定义了许多用于访问资源属性的方法。资源。getProperty(Property p)方法访问资源的属性。此方法不遵循通常的Java访问器约定,因为返回的对象类型是Statement,而不是您可能预期的Property。返回整个语句允许应用程序使用返回语句对象的一个访问器方法访问属性的值。例如,要检索作为vcard:N属性值的资源:
// retrieve the value of the N property |
通常,语句的对象可以是资源或文字,因此应用程序代码知道值必须是资源,就会强制转换返回的对象。Jena尝试做的事情之一是提供特定于类型的方法,以便应用程序不必强制转换,并且可以在编译时进行类型检查。上面的代码片段可以更方便地编写:
// retrieve the value of the N property |
类似地,可以检索属性的文字值:
// retrieve the given name property |
如果一个属性可能出现多次,则资源。listProperties(Property p)方法可用于返回一个迭代器,该迭代器将列出所有属性。此方法返回一个迭代器,该迭代器返回Statement类型的对象。我们可以这样列出昵称:
// set up the output |
可参见 https://github.com/apache/jena/tree/main/jena-core/src-examples/jena/examples/rdf/Tutorial06.java
具体代码如下:
public class Tutorial06 extends Object { |
2.7 查询模型
模型中listStatements()方法列出了模型中的所有语句,可能是查询模型的最粗糙方法。不建议在非常大的型号上使用。模型listSubjects()类似,但它返回一个迭代器,覆盖所有具有属性的资源,即某些语句的主题。
模型的listSubjectsWithProperty(Property p,RDFNode o)将在所有具有值为o的属性p的资源上返回一个迭代器。如果我们假设只有vcard资源具有vcard:FN属性,并且在我们的数据中,所有此类资源都具有这样的属性,那么我们可以找到这样的所有vcard:
// list vcards |
所有这些查询方法都只是原始查询方法model.listStatements(Selector s)模型上的语法糖。选择器接口设计为可扩展,但目前只有一个实现,即包org.apache.jena.rdf.model中的类SimpleSelector。在Jena中需要使用特定类而不是接口时,使用SimpleSelector是罕见的情况之一。SimpleSelector构造函数有三个参数:
Selector selector = new SimpleSelector(subject, predicate, object); |
此选择器将选择主题匹配、谓词匹配和对象匹配的所有语句。如果在任何位置提供了null,那么它将匹配任何内容;否则,它们匹配相应的相等资源或文字。(如果两个资源具有相等的URI或是相同的空白节点,则它们是相等的;如果两个字面值的所有组件都相等,则它们都是相同的。)因此:
Selector selector = new SimpleSelector(null, null, null); |
将选择模型中的所有语句。
Selector selector = new SimpleSelector(null, VCARD.FN, null); |
将使用VCARD选择所有语句。FN作为谓词,无论主语或宾语是什么。作为一种特殊的速记,
listStatements( S, P, O )等价于listStatements( new SimpleSelector( S, P, O ) )
// select all the resources with a VCARD.FN property |
输出大致如下:
The database contains vcards for: |
参见 https://github.com/apache/jena/tree/main/jena-core/src-examples/jena/examples/rdf/Tutorial08.java
public class Tutorial08 extends Object { |
2.8 模型合并
可以通过union合并两个模型:
Jena提供了三种操作来操作整个模型。这些是并集、交集和差集的公共集合运算。
两个模型的联合是表示每个模型的语句集的联合。这是RDF设计支持的关键操作之一。它允许合并来自不同数据源的数据。考虑以下两种模型:
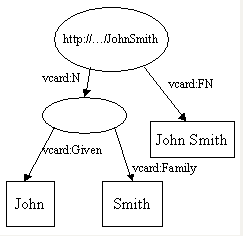
当它们合并时http://...JohnSmith节点合并为一个,并删除重复的vcard:FN弧以生成:
大致代码
// read the RDF/XML files |
输出如下
<rdf:RDF |
即使您不熟悉RDF/XML语法的细节,也应该很清楚模型已经按预期合并。模型的交集和差异可以用类似的方法计算,方法是:.intersection(Model)和.difference(Model);
代码参见 https://github.com/apache/jena/blob/main/jena-core/src-examples/jena/examples/rdf/Tutorial09.java
/** Tutorial 9 - demonstrate graph operations |
2.9 字面值和数据类型
RDF字面值不仅仅是简单的字符串。字面值可以有一个语言标记来指示文字的语言。带有英语标签的字面值(literal )“chat”被视为与带有法语标记的字面值(literal )“hat”不同。这种相当奇怪的行为是原始RDF/XML语法的产物。
此外,实际上有两种字面值。其中一个,字符串组件就是一个普通字符串。另一方面,字符串组件应该是一个平衡良好的XML片段。当RDF模型被写为RDF/XML时,使用parseType=’Literal’属性的特殊构造来表示它。
/** Tutorial 11 - more on literals |
输出如下:
<rdf:RDF |
具体代码参见 https://github.com/apache/jena/blob/main/jena-core/src-examples/jena/examples/rdf/Tutorial11.java
要将两个字面值视为相等,它们必须都是XML文字或都是简单文字。此外,两者都必须没有语言标记,或者如果存在语言标记,则它们必须相等。对于简单字面值,字符串必须相等。XML字面值有两个相等的概念。简单的概念是,前面提到的条件为真,字符串也相等。另一个概念是,如果字符串的规范化是相等的,那么它们可以是相等的。
Jena的接口还支持类型化字面值。老式的方式(如下所示)将类型化文字视为字符串的简写:类型化值以通常的Java方式转换为字符串,这些字符串存储在Model中。例如,尝试(注意,对于简单的字面值,我们可以省略model.createLiteral(…)调用):
// create the resource |
三 本体管理
具体参见官方文档 https://jena.apache.org/documentation/ontology/
3.1 简单实例
期待结果
<rdf:RDF |
大致代码如下:
OntModel m = ModelFactory.createOntologyModel(); |
实际输出如下:
<rdf:RDF |
3.2 Protege构建本体
最终效果
构建流程:
- 决定本体的领域和范围
- 考虑使用已有的本体(操作参考上篇文章)
- 例举本体中的关键项
- 确定类和类的结构
- 确定类的属性
- 确定属性的特点
- 创建实例(实体)
左上方的四个标签:
- Active Ontology:活跃本体
- Entity:实体信息
- Individual by Class:对象信息
- DL Query:DL查询
3.2.1 创建类
目标:
建立 人物 类:

3.2.2 添加类与类之间的约束
类与类之间的约束:互斥、子类、等价类、原子类等。
目标:
- 企业类与地点类互斥(如下)
- 有限责任公司类与股份有限公司类互斥
企业 类与 地点 类 互斥:
(如果没找到description 企业窗口,windows-views-class views-description)
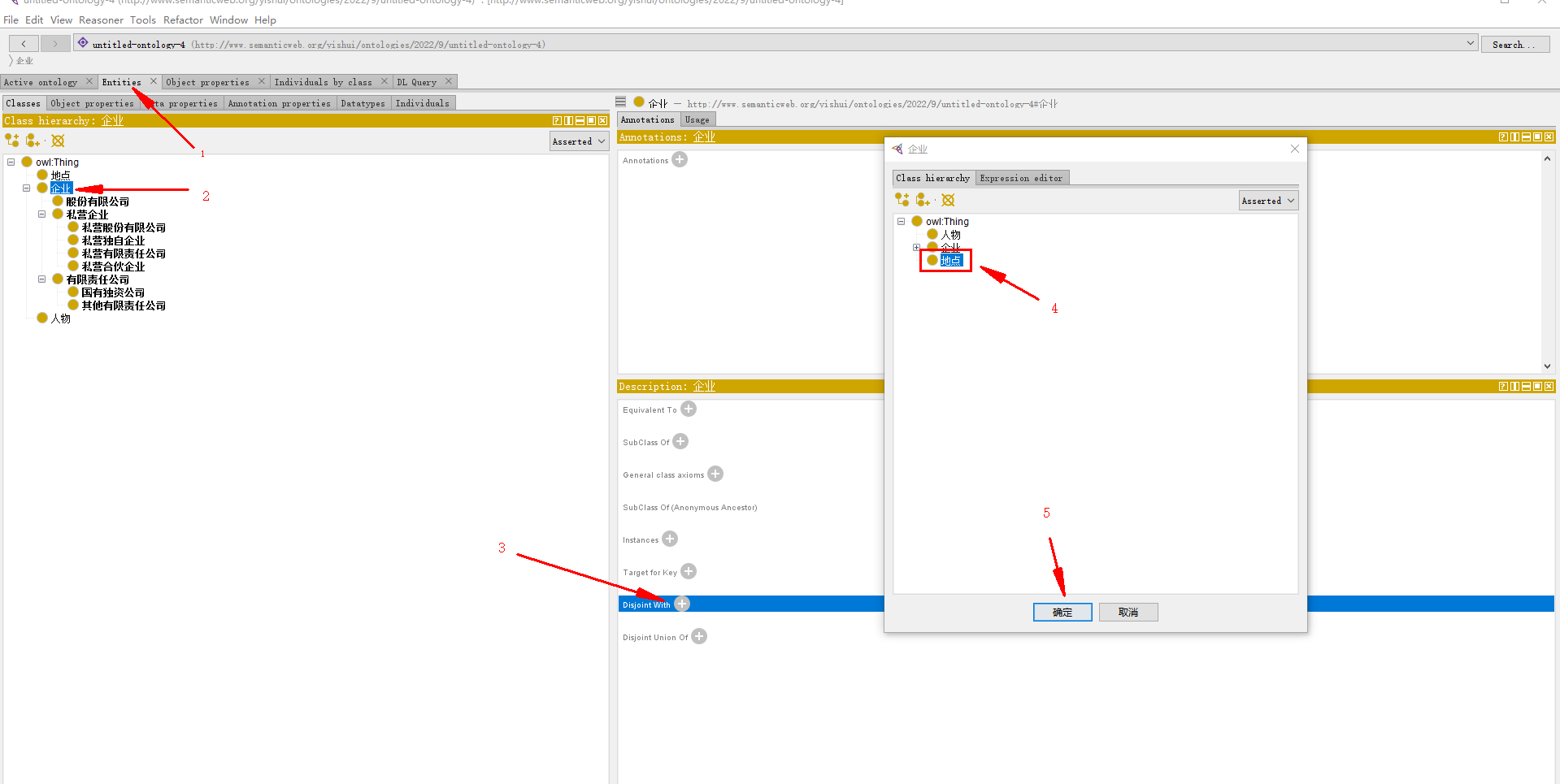
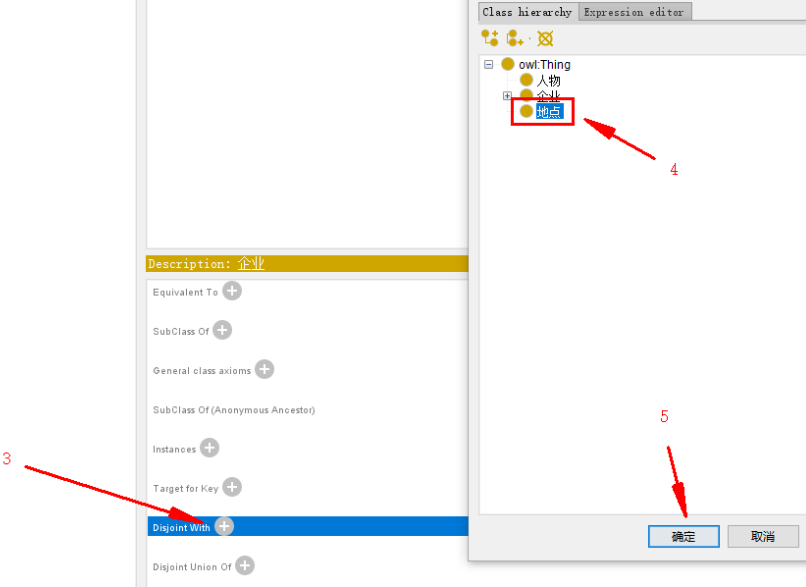
3.2.3 添加类的属性
3.2.3.1 对象属性(类与类的关系)
类 —–对象属性—–> 类
目标:
- 企业 —–上游—–> 企业
- 企业 —–下游—–> 企业
- 人物 —–总经理——> 企业
- 人物 —–法人——> 企业(如下)
- 地点 —–注册地——> 企业
添加对象属性: 法人
(如果没找到object properties,Windows – tabs – object properties)
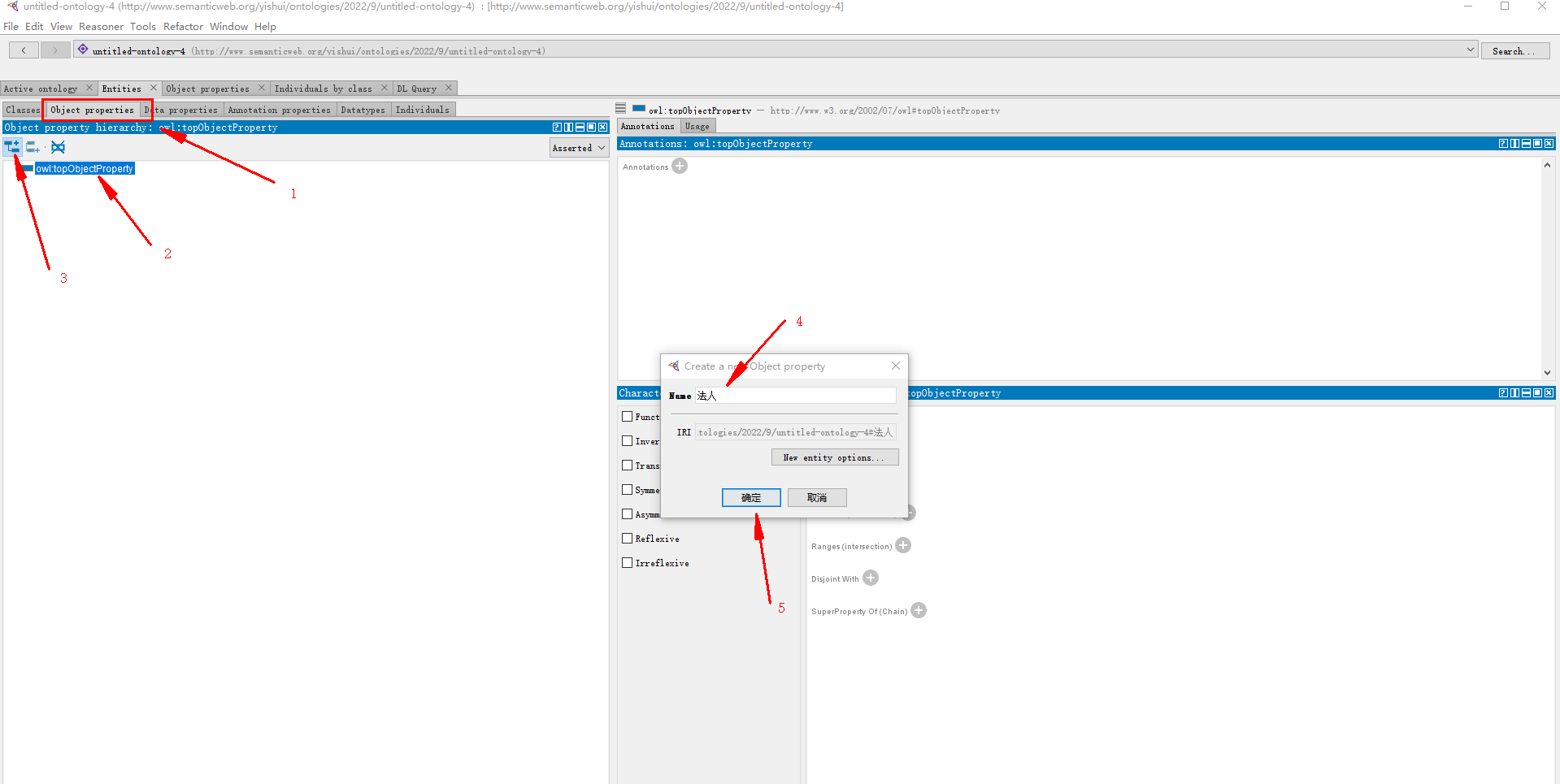
指定 法人 所属类 —— 人物 :
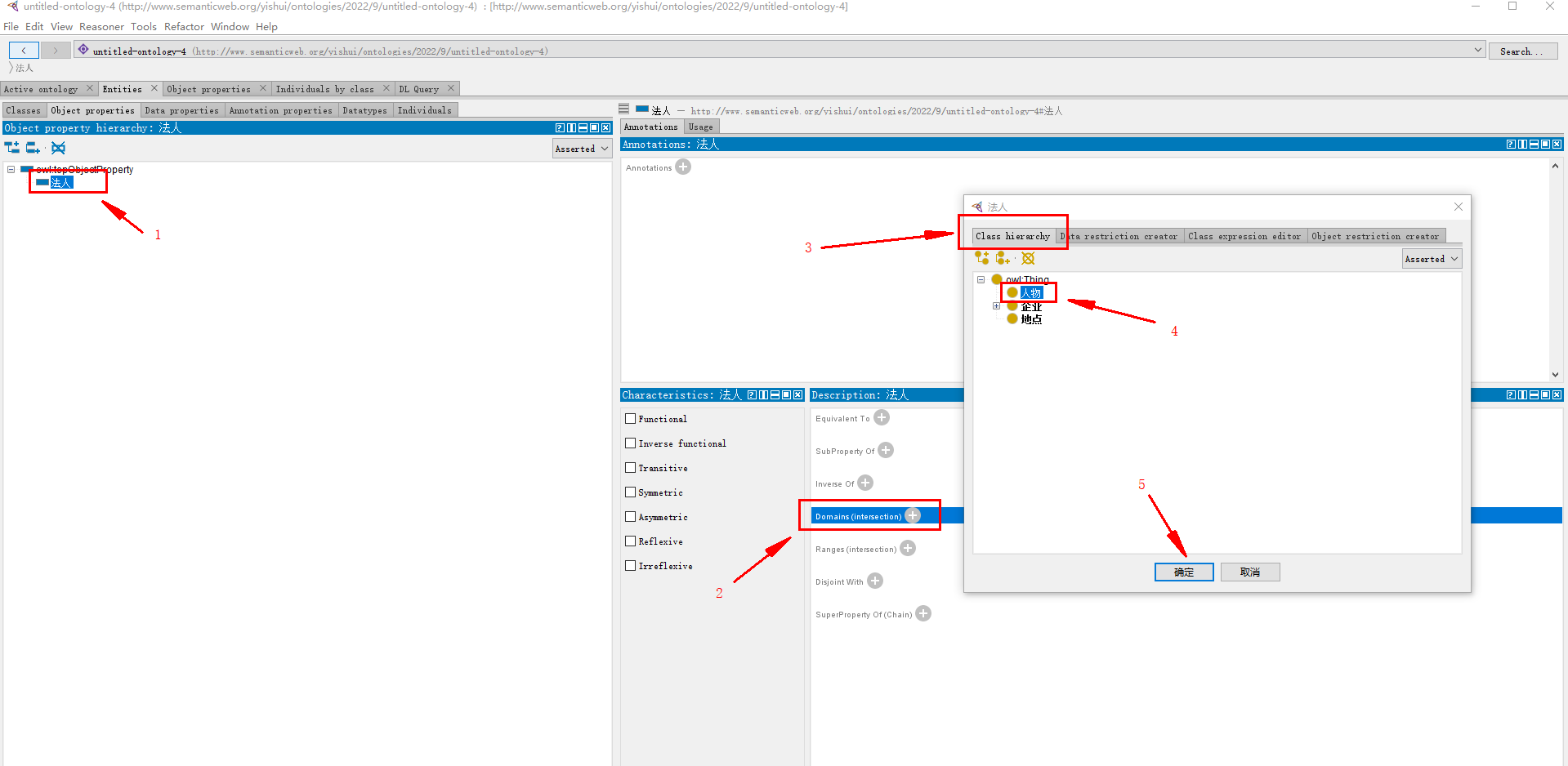
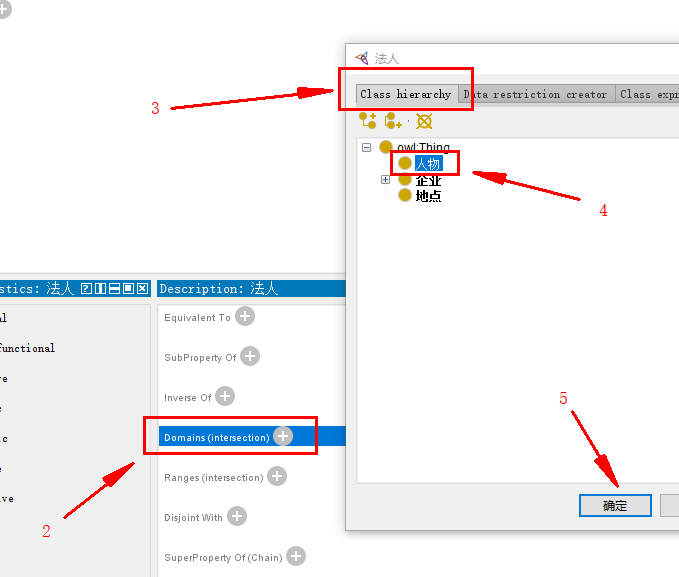
指向 企业 类:
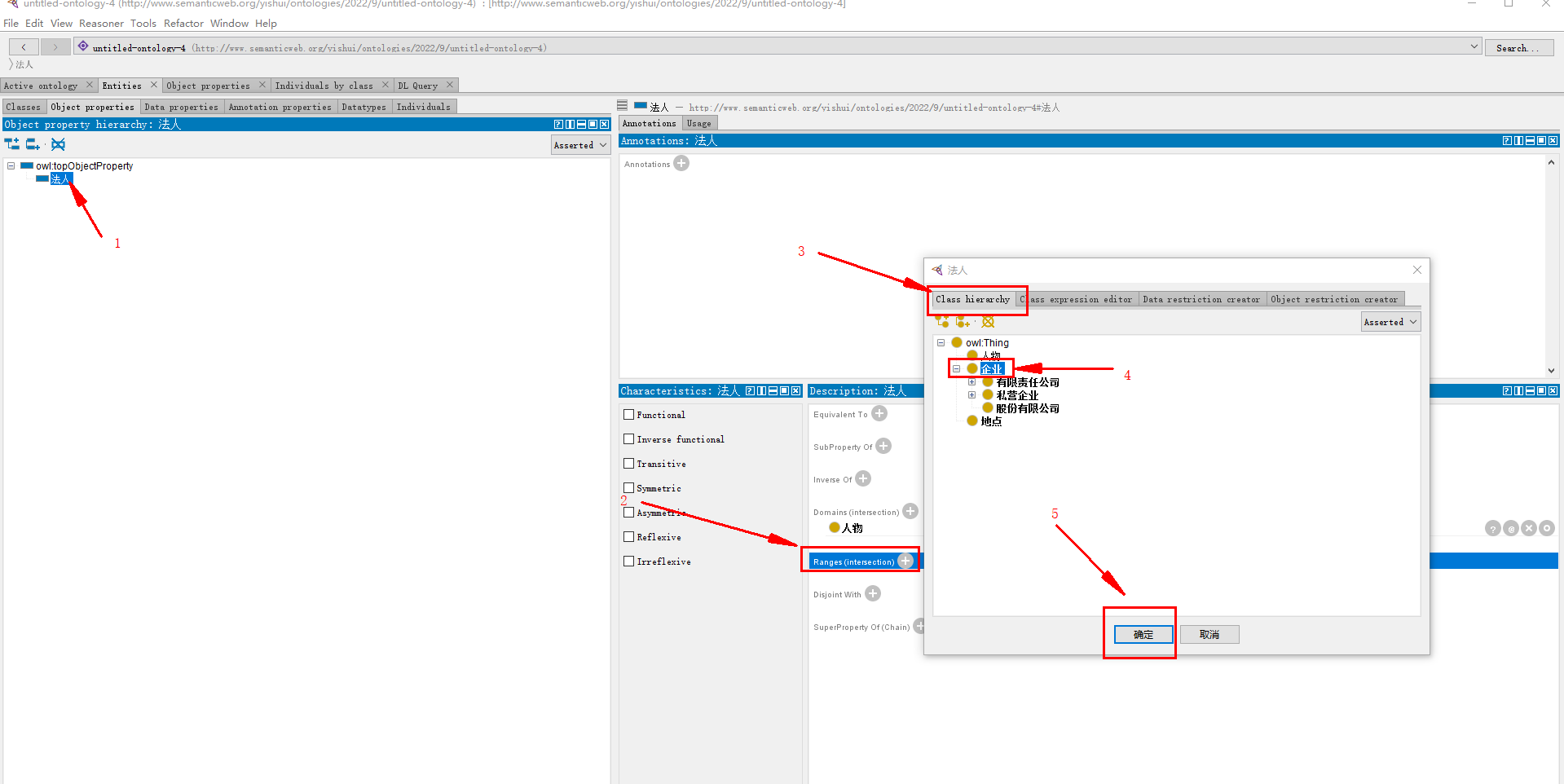
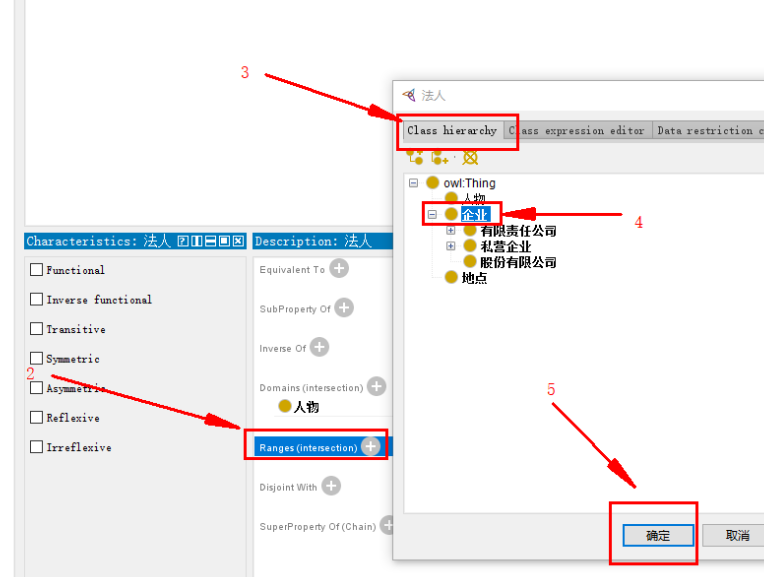
完整如下:

3.2.3.2 数据属性
类的数据属性及其数据类型
目标:
| 数据属性 | 类 | 类型 |
|---|---|---|
| 主营业务 | 企业 | string |
| 成立时间 | 企业 | string |
| 年龄 | 人物 | int |
| 性别 | 人物 | string |
添加数据属性: 主营业务
(如果没找到data properties,Windows – tabs – data properties)
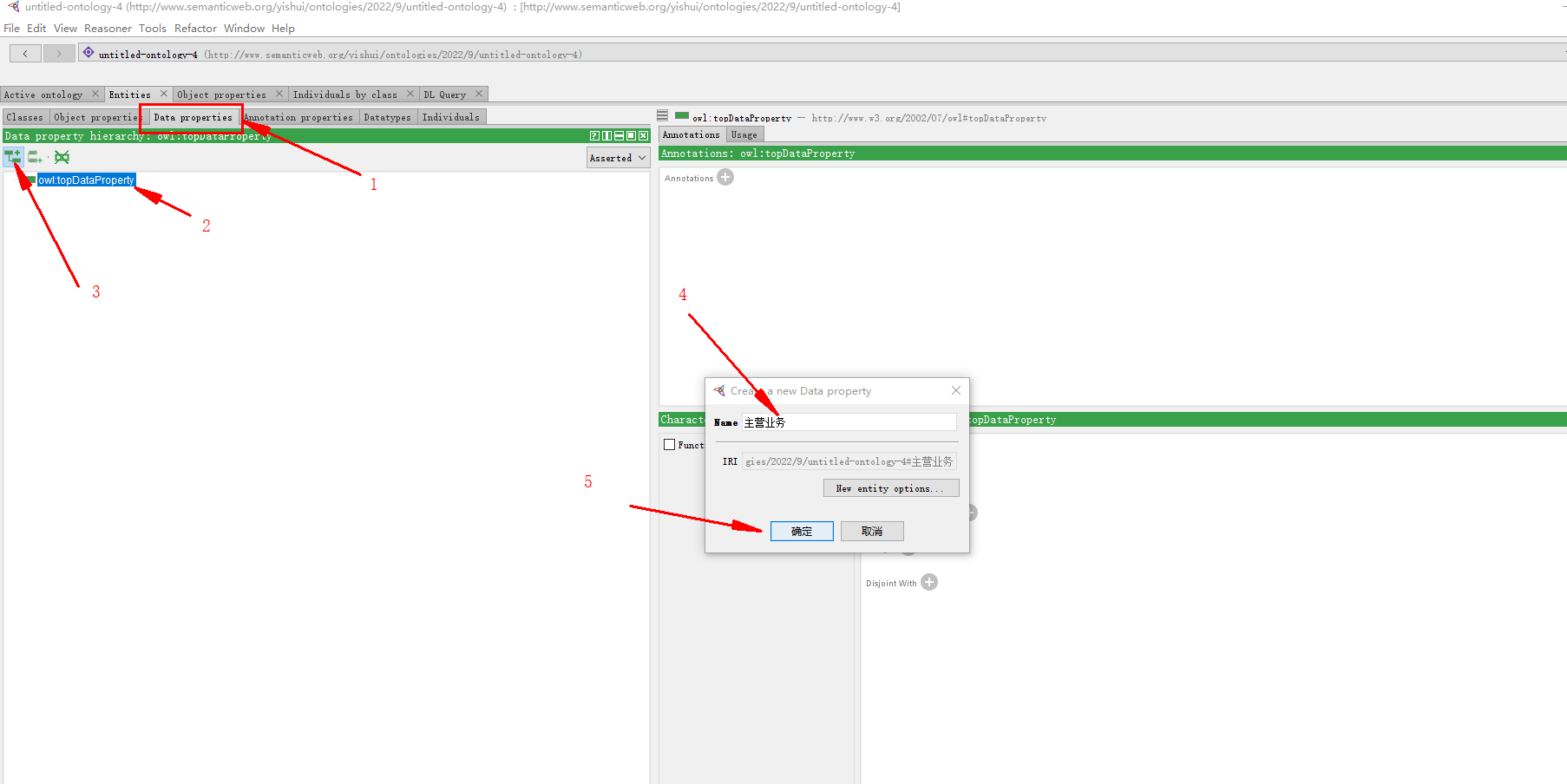
指定 主营业务 所属类 企业:
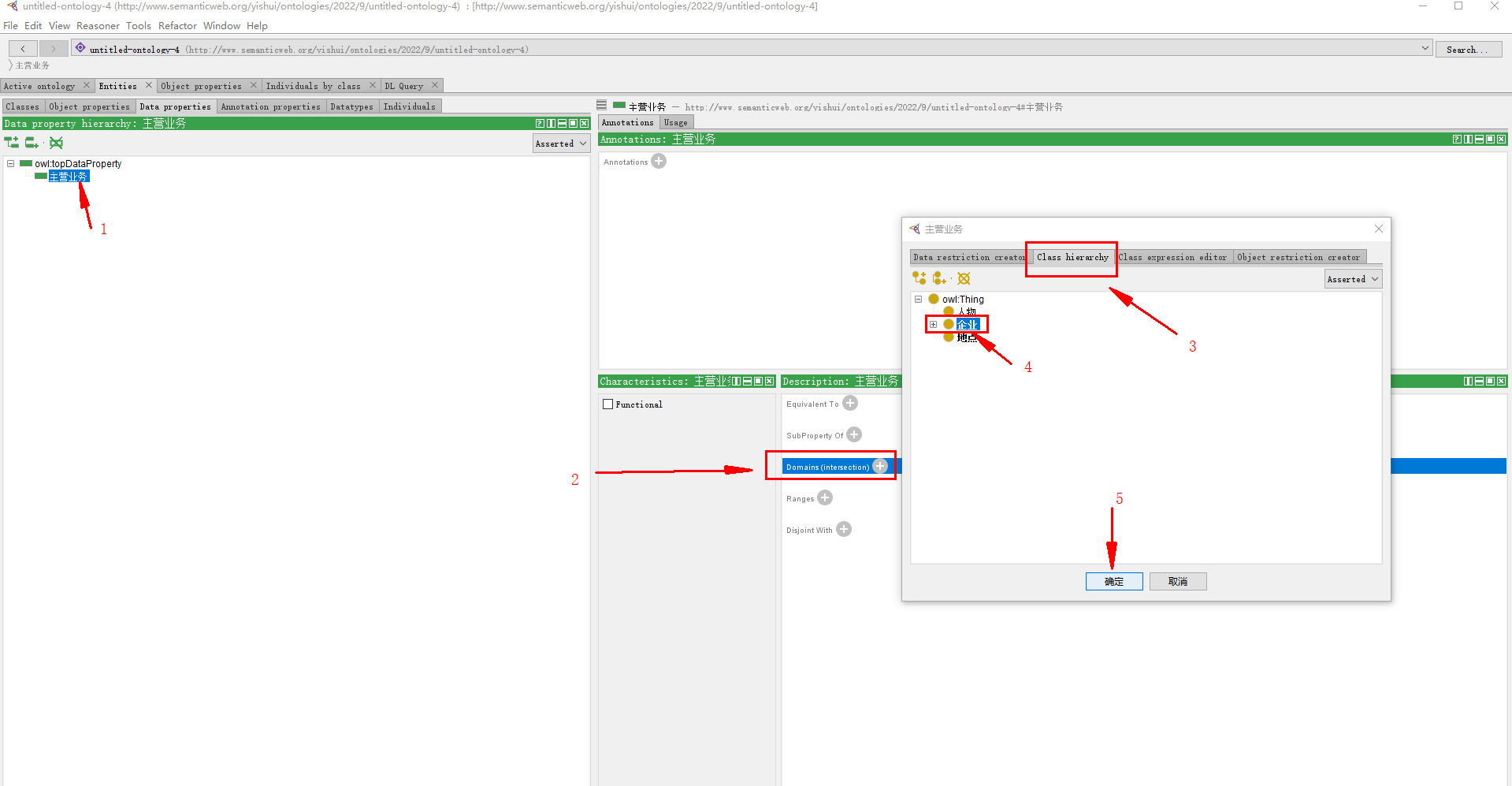
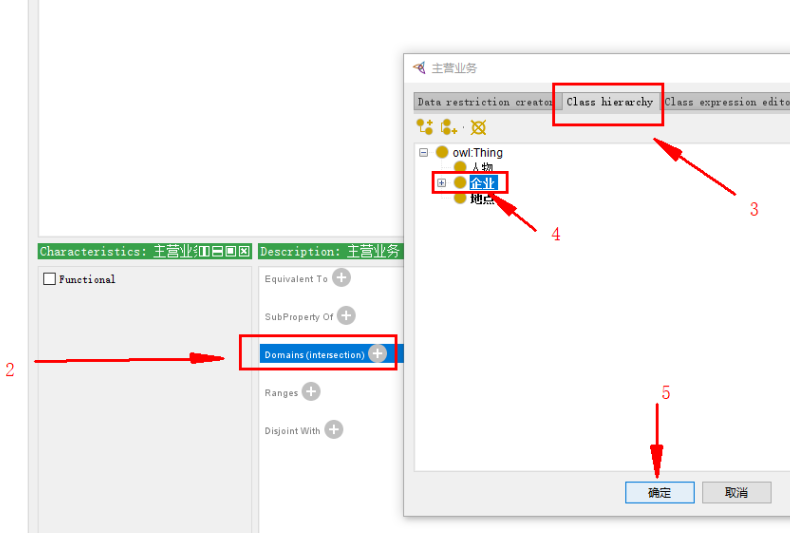
完整如图
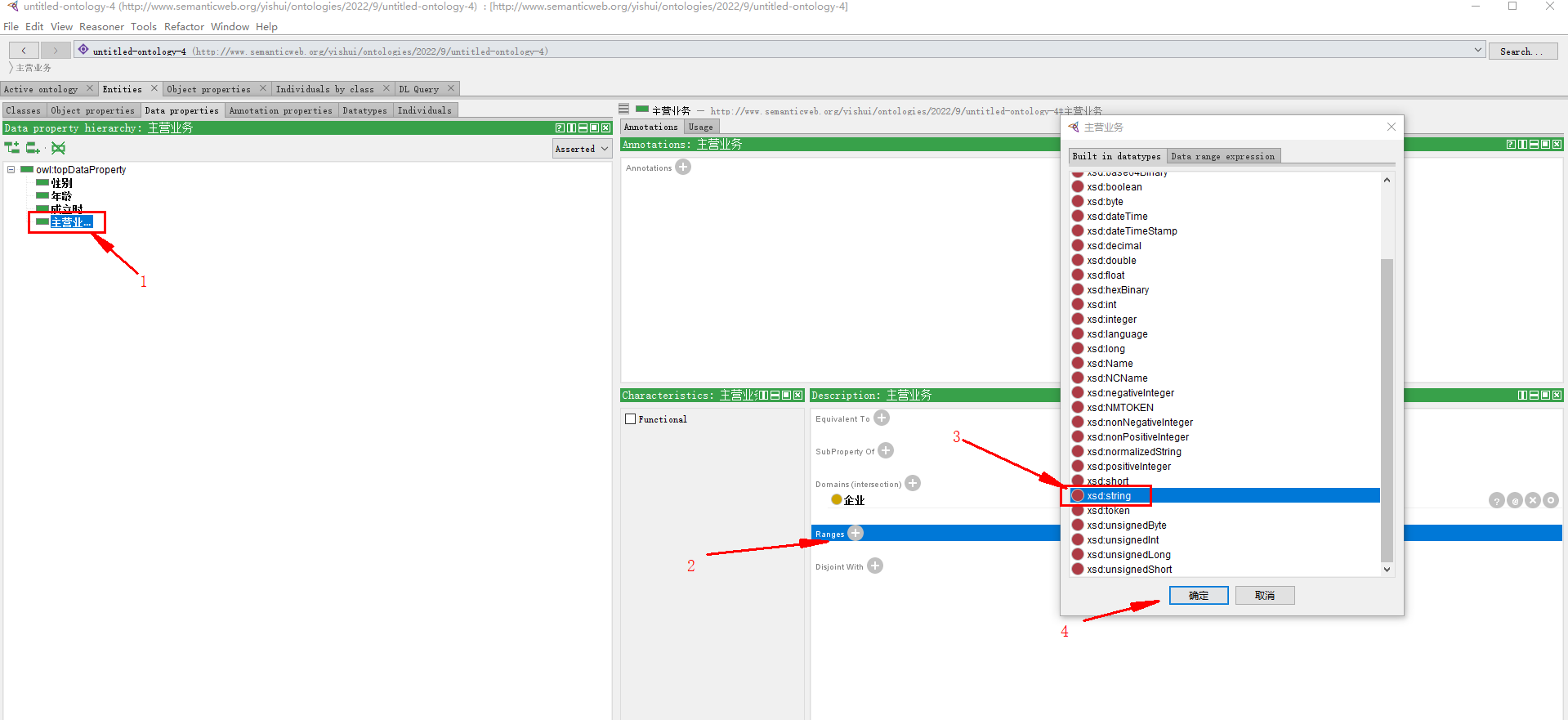
属性 主营业务 的数据类型:
接着上一步,找range
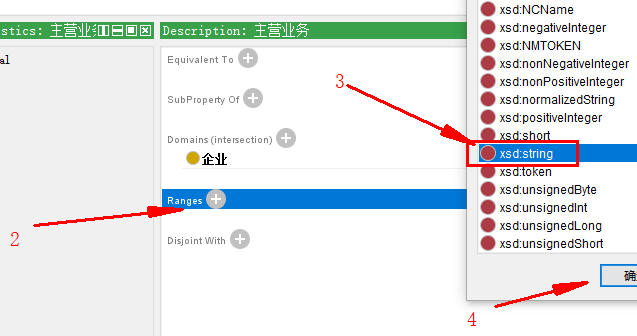
3.2.4 创建实例(实体)
目标:
| 实例 | 类 | 对象属性 | 数据属性 |
|---|---|---|---|
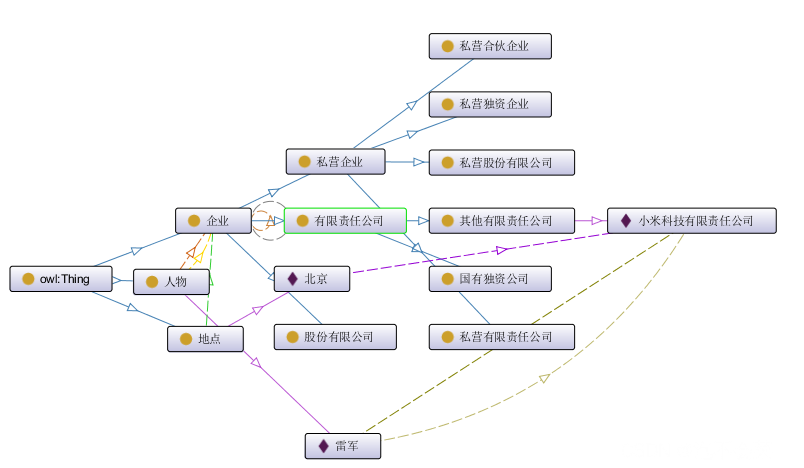
| 雷军 | 人物 | 1,法人 小米科技有限责任公司(如下) 2, 总经理 小米科技有限责任公司 | 1,性别(string) 男 2.年龄(int) 50 |
| 小米责任有限公司 | 其他有限公司 | 主营业务(string):技术开发、技术进出口、计算机等 | |
| 北京 | 地点 | 注册地 小米责任有限公司 |
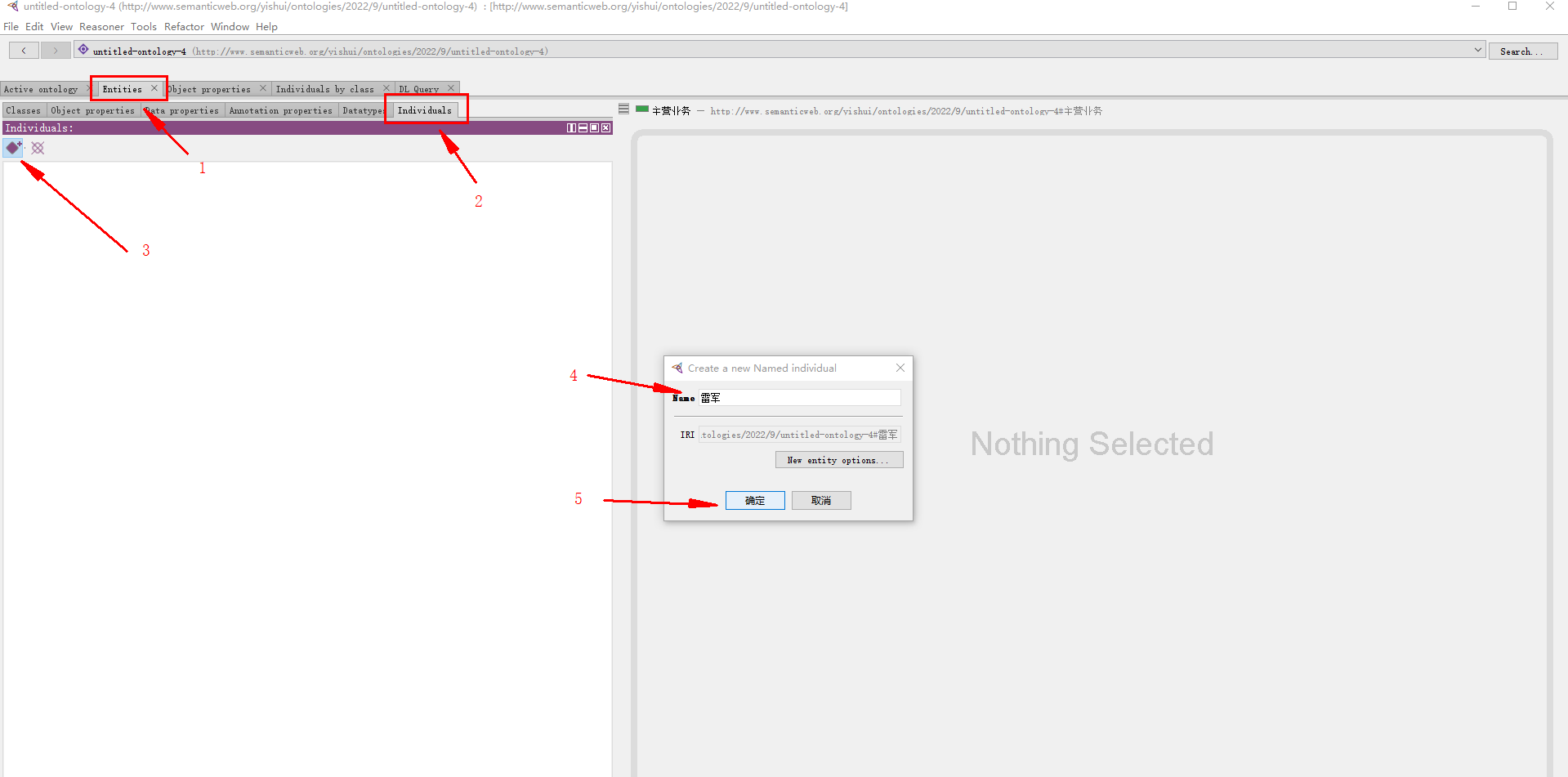
3.2.4.1 创建实例名称
创建实例 雷军:
(如果没找到individuals,Windows – views – individual views -individuals)
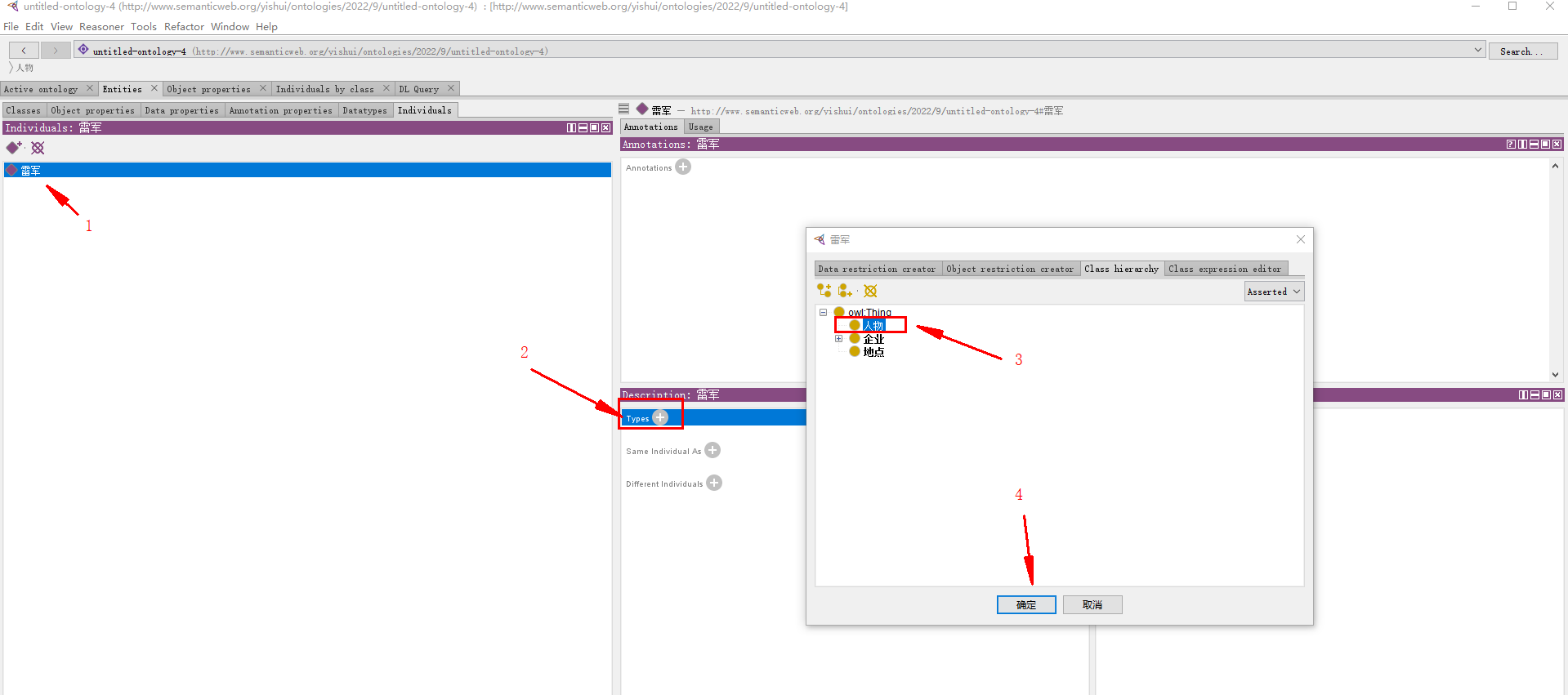
确定实例 雷军 所属的类 —— 人物:
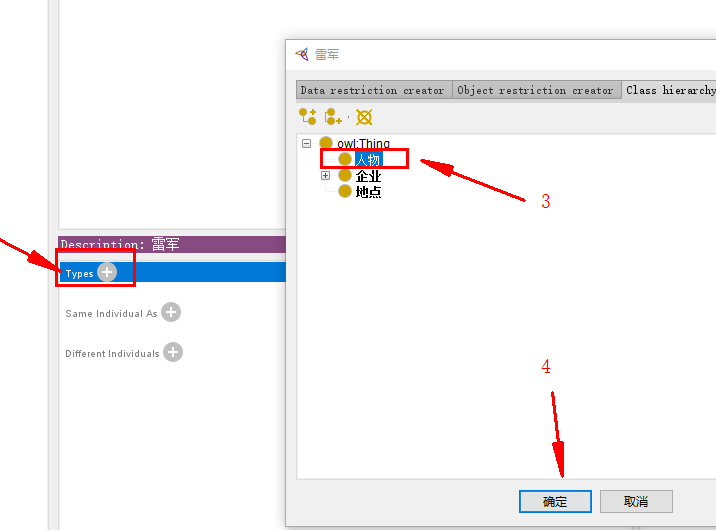
3.2.4.2 添加实体属性
3.2.4.2.1 对象属性
对于实例 雷军,填写其对象属性:
(3、4填写对象属性的名称、作用的另一实体)
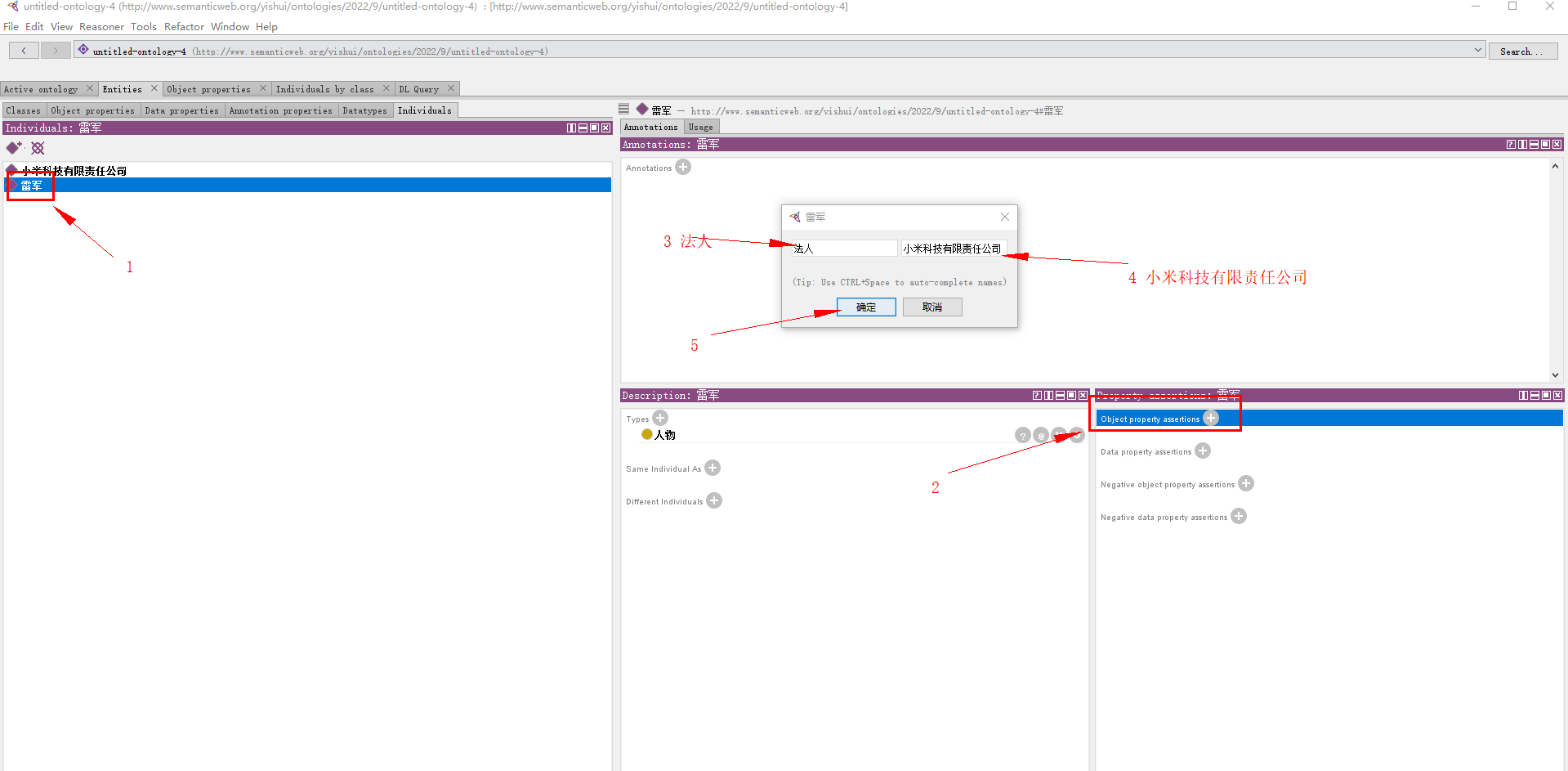

3.2.4.2.2 数据属性
对于实例 小米科技有限责任公司,填写其数据属性:

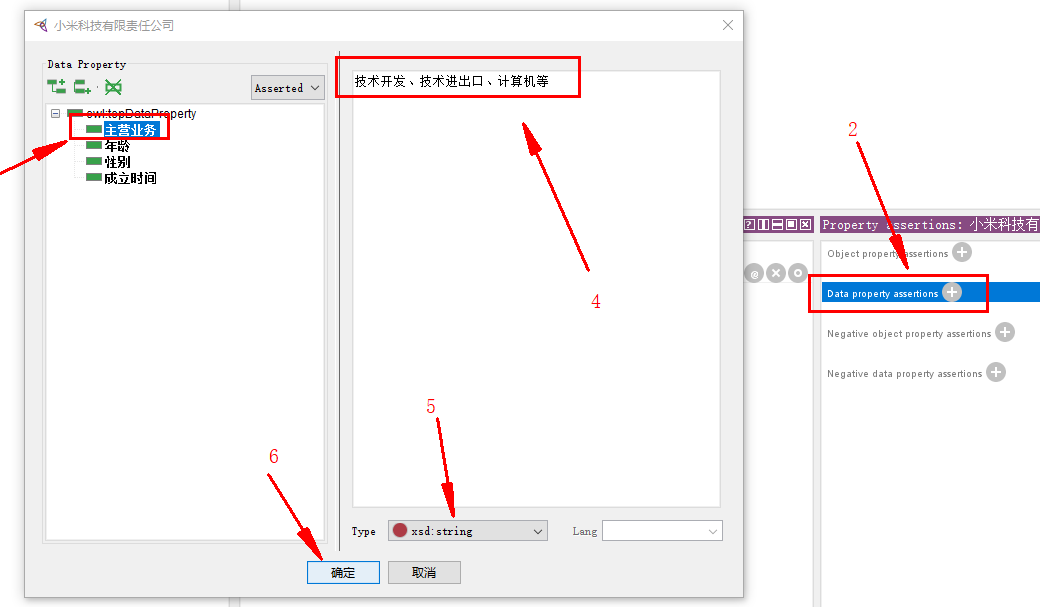
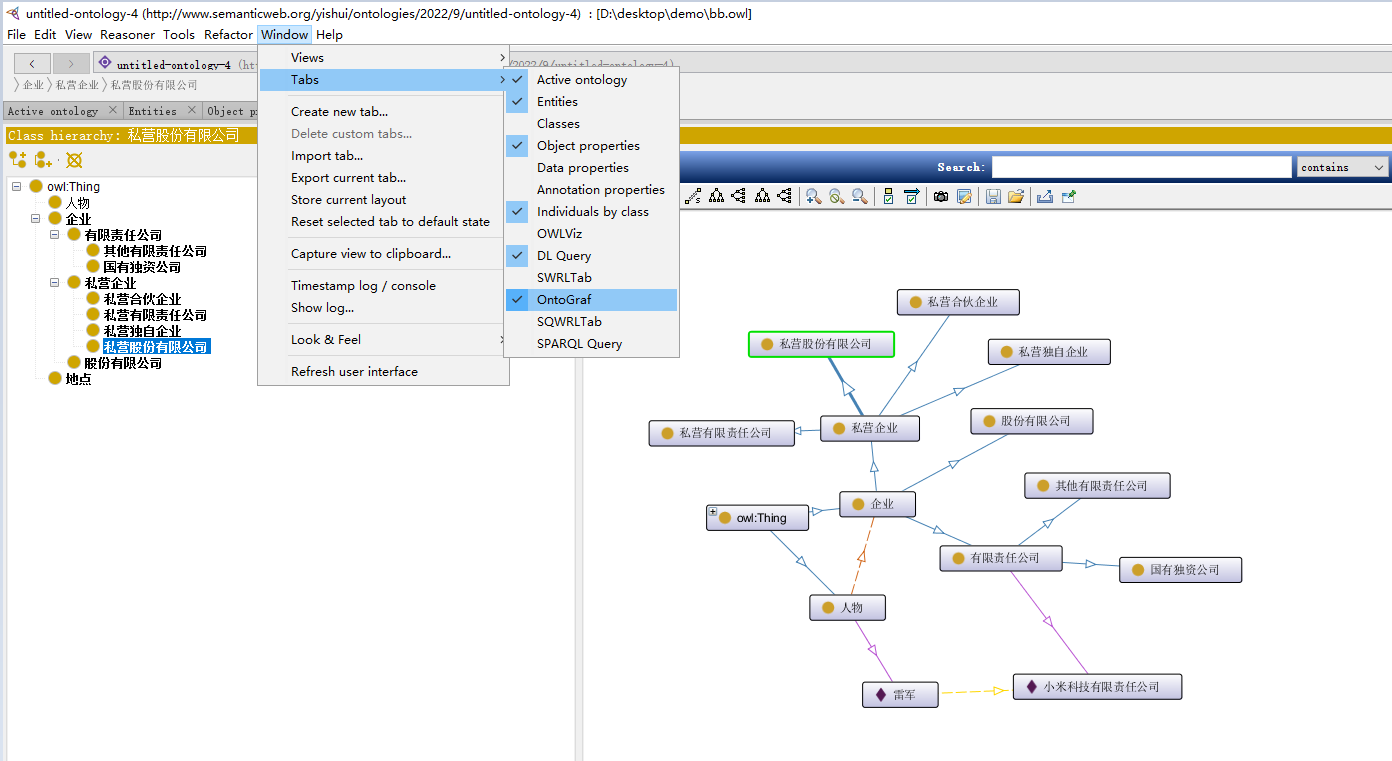
3.2.5 成果展示
3.3 API方式构建本体
参见文档 https://jena.apache.org/documentation/ontology/#creating-ontology-models
3.3.1创建本体模型
本体模型是Jena RDF模型的扩展,提供了处理本体的额外功能。本体模型是通过Jena ModelFactory创建的。创建本体模型的最简单方法如下:
OntModel m = ModelFactory.createOntologyModel(); |
这将创建一个具有默认设置的本体模型,这些设置是为了最大限度地与Jena的早期版本兼容。这些默认值为:
- OWL-Full language
- in-memory storage
- RDFS inference, which principally produces entailments from the sub-class and sub-property hierarchies.
这意味着默认的本体模型确实包含一些推断,这对模型的性能和模型中出现的三元组都有影响。
在许多应用程序中,例如驱动GUI,RDFS推理太强。例如每个类都被推断为owl:Thing的直接子类。在其他应用中,需要更强的推理能力。通常,要创建具有特定推理器或语言配置文件的OntModel,应该将模型规范传递给createOntologyModel调用。例如,完全不执行推理的OWL模型可以通过以下方式创建:
OntModel m = ModelFactory.createOntologyModel( OntModelSpec.OWL_MEM ); |
要为特定语言创建本体模型,但将所有其他值保留为默认值,您应该将本体语言的URI传递给模型工厂。各种语言配置文件的URI字符串为:
| Ontology language | URI |
|---|---|
| RDFS | http://www.w3.org/2000/01/rdf-schema# |
| OWL Full | http://www.w3.org/2002/07/owl# |
| OWL DL | http://www.w3.org/TR/owl-features/#term_OWLDL |
| OWL Lite | http://www.w3.org/TR/owl-features/#term_OWLLite |
3.3.2 通用本体类型:OntSource
本体API中表示本体值的所有类都将OntSource作为一个公共超类。这使得OntResource成为放置所有此类类的共享功能的好地方,并为常规方法提供了方便的公共返回值。Java接口OntResource扩展了Jena的RDF Resource接口,因此任何接受资源或RDFNode的通用方法也将接受OntResoource,从而接受任何其他本体值。
通过OntResource上的方法表示的本体资源的一些常见属性如下所示:
| Attribute | Meaning |
|---|---|
versionInfo |
记录此资源的版本或历史的字符串 |
comment |
与此值关联的一般注释 |
label |
人类可读标签 |
seeAlso |
有关此资源的详细信息,请参阅另一个web位置 |
isDefinedBy |
A specialisation of seeAlso that is intended to supply a definition of this resource |
sameAs |
Denotes another resource that this resource is equivalent to |
differentFrom |
Denotes another resource that is distinct from this resource (by definition) |
对于这些属性中的每一个,都有可用方法的标准模式:
| Method | Effect |
|---|---|
add<property> |
为给定属性添加附加值 |
set<property> |
删除属性的所有现有值,然后添加给定值 |
list<property> |
返回覆盖属性值的迭代器 |
get<property> |
如果资源具有给定属性,则返回该属性的值。如果不是,则返回null。如果它有多个值,则进行任意选择。 |
has<property> |
如果给定属性至少有一个值,则返回true。根据属性的名称,有时是<property> |
remove<property> |
从该资源的属性值中删除给定值。如果资源没有该值,则不起作用。 |
For example: addSameAs( Resource r ), or isSameAs( Resource r ). For full details of the individual methods, please consult the Javadoc.
OntSource定义了其他一些通用实用程序方法。例如要了解资源对于给定属性有多少值可以调用getCardinality(property p)。要从本体中完全删除资源可以调用remove()。这样做的效果是删除将此资源作为语句的主题或对象的每个语句。
要获取给定属性的值请使用getPropertyValue(property p)。要设置它请使用setPropertyValue( Property p, RDFNode value )。继续命名模式可以列出命名属性的值(使用listPropertyValues)、删除(使用removeProperty)或添加(使用addProperty)。
最后,OntResource提供了列出、获取和设置资源的rdf:type的方法,该方法表示资源所属的类(注意,在rdf和OWL中,资源可以同时属于多个类)。type属性是在各种本体语言的语义模型中定义了许多蕴涵规则的属性之一。因此,listRDFTypes()返回的值通常更多地依赖于绑定到本体模型的推理器。例如,假设我们有类A,类B是A的子类,资源x的断言rdf:type是B。如果没有reasoner,列出x的rdf类型将只返回B。如果reasoner能够计算子类层次结构的闭包(大多数情况下都可以),x的rdf类型也将包括A。一个完整的OWL reasoner还将推断x具有rdf:type OWL:Thing和rdf:resource。
对于某些任务,获取资源的RDF类型的完整列表正是所需的。对于其他任务,情况并非如此。例如,如果您正在开发本体编辑器,您可能希望在其显示中区分推断类型和断言类型。在上面的示例中,只断言了xrdf:type B,其他所有内容都是推断出来的。进行这种区分的一种方法是使用基本模型。从基本模型获取资源并列出其中的类型属性将只返回断言值。例如:
// create the base model |
对于其他用户界面或表示任务,我们可能需要类型的完整列表和仅声明值的基本列表之间的内容。考虑图中的类层次结构:
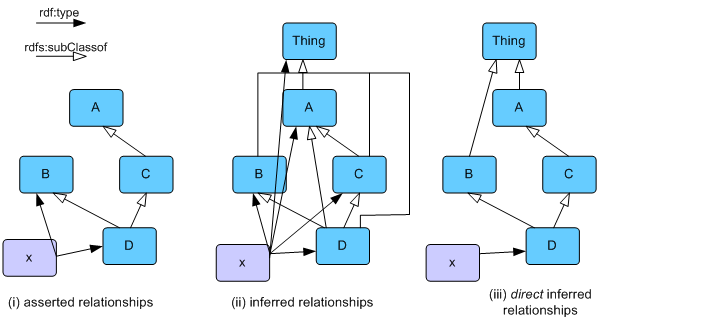
图(i)显示了一个基本模型,其中包含一个类层次结构和一个实例x。图(ii)显示了可以从这个基本模型推断出的一整套关系。在图(iii)中,我们只看到直接或最大特定的关系。例如,在(iii)中,x没有rdf:type A,因为这是一个关系,而x有rdf:type D,而D是A的子类。还请注意,出于类似的原因,rdf:TypeB链接也从直接图中删除了。因此,直接图对推断图和断言图都隐藏了关系。在用户界面中显示实例x时,特别是在某种树状视图中,直接图通常最有用,因为它以最紧凑的形式包含有用的信息。
要列出资源的RDF类型,请使用:
listRDFTypes() // assumes not-direct |
3.3.3 本体类和基本类表达式
类是本体的基本构建块。在Jena中,一个简单的类由一个OntClass对象表示。如上所述,本体类是RDF资源的一个方面。因此,获取本体类的一种方法是将普通RDF资源转换为其类方面。假设m是一个适当定义的OntModel,ESWC本体已被读入其中,NS是一个表示本体名称空间的变量:
Resource r = m.getResource( NS + "Paper" ); |
这可以通过在本体模型上调用getOntClass()来简写:
OntClass paper = m.getOntClass( NS + "Paper" ); |
getOntClass方法将检索具有给定URI的资源,并尝试获取OntClasss方面。如果其中任何一个操作失败,getOntClass()将返回null。将其与createClass方法进行比较,该方法将尽可能重用现有资源,否则将创建新的类资源:
OntClass paper = m.createClass( NS + "Paper" ); |
您可以使用create-class方法创建一个匿名类——一个没有关联URI的类描述。在OWL中构建更复杂的本体时,常常使用匿名类。它们在RDFS中用处不大。
OntClass anonClass = m.createClass(); |
一旦有了本体类对象,就可以通过在OntClass上定义的方法开始处理它。类的属性处理方式与上面的OntResource的属性类似,它有一组方法来设置、添加、获取、测试、列出和删除值。以这种方式处理的类的属性包括:
| Attribute | Meaning |
|---|---|
| subClass | 此类的子类,即声明为subClassOf此类的类。 |
| superClass | 此类的超类,即此类是subClassOf的类. |
| equivalentClass | 表示与此类相同概念的类。这不仅仅是有相同的阶级扩展:“2003年英国首相”阶级与“切里·布莱尔的丈夫”阶级包含相同的个体,但它们代表不同的概念。 |
| disjointWith | 表示与此类没有共同实例的类。 |
因此,在我们的示例本体中,我们可以打印Artefact的子类列表,如下所示:
OntClass artefact = m.getOntClass( NS + "Artefact" ); |
注意,在RDFS和OWL语义下,每个类都是其自身的子类(换句话说,RDFS:subClassOf是自反的)。虽然这在语义上是正确的,但Jena用户报告说,他们发现这很不方便。因此,listSubClasses和listSuperClasses便利方法从迭代器返回的结果列表中删除反身。但是,如果您使用普通模型API查询rdfs:subClassOf三元组,假设使用了推理器,则自反三元组将出现在推导出的三元组中。
给定一个OntClass对象,您可以使用以下方法创建或删除类扩展的成员(作为类实例的个体):
| Method | Meaning |
|---|---|
| listInstances() listInstances(boolean direct) | 返回那些在rdf:type值中包含此类的实例的迭代器。direct标志可用于选择作为类的直接成员的个人,而不是通过类层次结构间接选择。因此,如果p1具有rdf:type:Paper,它将出现在由Artefact上的listInstances返回的迭代器中,但不会出现在由:Artefacts上的listInstances(false)返回的迭代器中。 |
| createIndividual() createIndividual(String uri) | 向模型添加一个资源,其断言的rdf:type就是这个本体类。如果没有给出URI,则个人是匿名资源。 |
| dropIndividual(Resource individual) | 删除给定个体与此本体类之间的关联。实际上,这会删除此类和资源之间的rdf:type链接。请注意,这与完全删除个体不同,除非关于资源的唯一已知信息是它是类的成员。要删除OntSource,包括类和个体,请使用remove()方法。 |
要测试类是否是此模型中类层次结构的根(即它没有已知的超类),请调用isHierarchyRoot()。
如果某个属性显示为语句主题,则该属性的域旨在允许包含有关个人类的内容。它不是一个可以像XML模式那样用于验证文档的约束。然而,许多开发人员发现,使用属性的域来记录设计意图(该属性仅适用于域类的已知实例)是很方便的。鉴于此,显示域类中包含此类的属性是一个有用的调试或显示助手。方法listDeclaredProperties()尝试标识要应用于此类实例的属性。使用listDeclaredProperties在RDF框架how-to中有详细说明。
3.3.4 本体属性
在本体中,属性表示资源之间或资源与数据值之间关系的名称。它对应于逻辑表示中的谓词。RDFS和OWL的一个有趣的方面是,属性并没有被定义为某些封闭类的方面,而是它们本身就是一级对象。这意味着本体和本体应用程序可以直接存储、检索和断言属性。因此,Jena有一组Java类,允许您方便地操作本体模型中表示的属性。
本体模型中的属性是核心Jena API类property的扩展,允许访问关于本体语言中属性的附加信息。用于在Java中表示本体属性的常见API超类是OntProperty。同样,使用add、set、get、list、has和remove方法的模式,我们可以访问OntProperty的以下属性:
| Attribute | Meaning |
|---|---|
| subProperty | A sub property of this property; i.e. a property which is declared to be a subPropertyOf this property. If p is a sub property of q, and we know that A p B is true, we can infer that A q B is also true. |
| superProperty | A super property of this property, i.e. a property that this property is a subPropertyOf |
| domain | 表示构成此属性域的类。多个域值被解释为连接。域表示属性映射的值的类别。 |
| range | 表示构成此属性范围的一个或多个类。多个范围值被解释为连接。范围表示属性映射到的值的类别。 |
| equivalentProperty | 表示与此属性相同的属性。 |
| inverse | 表示与此属性相反的属性。因此,如果q是p的逆,并且我们知道A q B,那么我们可以推断B p A。 |
在示例本体中,属性hasProgramme具有OrganizedEvent域、一系列Programme和人类可读标签“has program”。我们可以在空本体模型中重建此定义,如下所示:
OntModel m = ModelFactory.createOntologyModel( OntModelSpec.OWL_MEM ); |
作为进一步的例子,我们可以选择向现有本体添加信息。要添加超级属性hasDeadline,要概括表示提交截止日期、通知截止日期和相机就绪截止日期的单独属性,请执行以下操作:
OntModel m = ModelFactory.createOntologyModel( OntModelSpec.OWL_MEM ); |
注意,尽管我们在表示新超级属性的对象上调用了addSubProperty方法,但本体的序列化形式将在每个子属性资源上包含rdfs:subPropertyOf公理,因为这是语言定义的。一般来说,Jena将尝试允许从任意方向对称访问子属性和子类。
3.3.5 对象和数据类型属性
OWL将RDF中的基本属性类型细化为两个子类型:对象属性和数据类型属性(有关更多详细信息,请参阅[OWL Reference])。它们之间的区别在于,对象属性在其范围内只能有个数,而数据类型属性在其区域内只能有具体的数据字面值。一些OWL推理器能够利用对象和数据类型属性之间的差异,对本体进行更有效的推理。OWL还添加了一个注释属性,该属性被定义为没有语义蕴涵,因此在注释本体文档时很有用,例如。
在Jena中,Java接口ObjectProperty、DatatypeProperty和AnnotationProperty是OntProperty的子类型。然而,他们没有自己特有的行为(方法)。它们的存在允许ObjectProperty的更复杂的子类型(传递属性等)在类层次结构中保持独立。然而,当您在模型中创建对象属性或数据类型属性时,它将产生在底层三元组存储中断言不同rdf:type语句的效果。
3.3.6 Functional properties
OWL允许对象和数据类型属性发挥作用——也就是说,对于域中的给定个体,范围值将始终相同。特别是,如果父亲是一种功能性财产,并且是个人:jane有父亲:jim和父亲:james,推理者有权得出结论:jim与james表示同一个人。函数属性相当于声明该属性的最大基数为1。
功能属性是通过本体属性对象的FunctionalProperty方面来表示的。如果属性被声明为函数性(使用isFunctional()方法进行测试),那么asFunctionalProperty()方法将方便地返回函数属性方面。非函数属性可以通过convertToFunctionalProperty()方法变为函数属性。创建属性对象时,还可以选择将布尔参数传递给OntModel上的createObjectProperty()方法。
3.3.7 Other property types
ObjectProperty有几个附加的子类型,表示本体属性的附加功能。TransitiveProperty意味着如果p是可传递的,并且我们知道:A p:b和b p:c,我们可以推断:A p:c。对称性意味着如果p是对称的,并且我们知道:ap:b,我们可以推断:bp:A。InverseFunctionalProperty意味着对于任何给定的范围元素,域值都是唯一的。
假设所有属性都是RDFNode对象,因此支持as()方法,您可以使用as()将对象属性方面更改为可传递属性方面。为了更直观,OntProperty Java类有许多方法支持直接切换到相应的方面视图:
public TransitiveProperty asTransitiveProperty(); |
这些方法都假设底层模型将支持这种视角上的变化。否则,操作将失败,并显示ConversionException。例如,如果给定的属性p在底层RDF模型中未被断言为可传递属性,那么调用p.asTransitiveProperty()将引发转换异常。如有必要,以下方法将添加附加信息(即附加rdf:type语句),以允许成功转换到备用方面。
public TransitiveProperty convertToTransitiveProperty(); |
有时,不检查底层数据是否支持.as()转换是很方便的。例如,如果开发人员知道转换是正确的,并且给出了当前未加载的外部本体的信息,则可能会出现这种情况。要允许.as()始终成功,请将OntModel对象的属性strictMode设置为false:myOntModel.setStrictMode( false )。
3.3.8 实例或个人
在OWL Full中,任何值都可以是一个单独的,因此是RDF图中三元组的主题,而不是本体声明。在OWL-Lite和DL中,根据语言的定义,应用程序使用的语言术语和实例数据是分开的。因此,Jena支持一个简单的个人概念,它本质上是Resource的别名。虽然Individuals在很大程度上与Resources同义,但它们确实提供了与本体API中其他Java类一致的编程接口。
创建个人有两种方法。两者都需要个人最初所属的类别:
OntClass c = m.createClass( NS + "SomeClass" ); |
这些方法之间唯一的真正区别是,第二种方法将在类附加到的同一模型中创建个体(请参见getModel()方法)。在上述两个示例中,都对个人进行了命名,但这不是必需的。OntModel方法中的createIndivual(Resource cls)创建属于给定类的匿名个人。请注意,类参数的类型仅为Resource。在调用此方法之前,您不需要使用as()向OntClass呈现Resource,尽管OntClasss当然是一个Resource所以使用Ont Class会很好地工作。
Individual提供了一组用于测试和操作个人所属的本体类的方法。这很方便:OWL和RDFS通过rdf:type属性表示类成员身份,用于操作和测试rdf:type的方法在OntSource上定义。您可以交替使用这两种方法。
3.3.9 完整代码
对应3.2 中的完整代码如下:
package com.demo.common.graph; |
输出的数据如下:
<rdf:RDF |
参考资料
- W3C 菜鸟RDF 教程 https://www.runoob.com/rdf/rdf-tutorial.html
- W3c菜鸟RDFS 教程 https://www.runoob.com/rdf/rdf-schema.html
- W3c菜鸟OWL 教程 https://www.runoob.com/rdf/rdf-owl.html
- Apache jena https://jena.apache.org/documentation/io/
- 知识图谱学习笔记(1) https://www.cnblogs.com/xiaoqi/p/kg-study-part-1.html
- 知识图谱推理与实践 (2) — 基于jena实现规则推理 https://www.cnblogs.com/xiaoqi/p/kg-inference-2.html
- 知识图谱推理与实践(3) — jena自定义builtin https://www.cnblogs.com/xiaoqi/p/kg-inference-3.html
- 图数据库之TinkerPop Provider https://www.cnblogs.com/xiaoqi/p/tinkerPop-Provider.html
- 知识图谱推理与实践(1) https://www.cnblogs.com/xiaoqi/p/kg-inference-1.html
- 面试官:说一下Jena推理 https://zhuanlan.zhihu.com/p/393136740
- sparql 查询语句快速入门 https://www.cnblogs.com/xiaoqi/p/sparql.html
- 图数据库查询语言 https://www.cnblogs.com/xiaoqi/p/graph-query-lang.html
- rdf4j github https://www.cnblogs.com/xiaoqi/p/graph-query-lang.html
- rdf4j 文档 https://rdf4j.org/documentation/tutorials/getting-started/
- 知识图谱——语义网中的知识表示 https://zhuanlan.zhihu.com/p/497471449
- protege5 本体(2)本体构建 入门 https://blog.csdn.net/weixin_44763868/article/details/122827519