一 pandas Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy (提供高性能的矩阵运算)。
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
Pandas 应用:
Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数典型用例。
数据结构
Series
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
1.1 pandas安装 导入 pandas 一般使用别名 pd 来代替:
查看 pandas 版本
import pandas as pdprint(pd.__version__)
运行结果为
import sys; print('Python %s on %s' % (sys.version, sys.platform))sys.path.extend(['F:\\python' , 'F:/python' ]) PyDev console: starting. Python 3.9 .5 (tags/v3.9 .5 :0 a7dcbd, May 3 2021 , 17 :27 :52 ) [MSC v.1928 64 bit (AMD64)] on win32
1.2 数据结构 - Series Pandas Series 类似表格中等一个列(column),类似于一维数组,可以保存任何数据类型 Series 由索引(index)和列组成,函数如下:
pandas.Series( data, index, dtype, name, copy)
参数说明:
data :一组数据(ndarray 类型)。index :数据索引标签,如果不指定,默认从 0 开始。dtype :数据类型,默认会自己判断。name :设置名称。copy :拷贝数据,默认为 False。
1.2.1 基本使用 示例代码
import pandas as pda = [1 , 2 , 3 ] myvar = pd.Series(a) print(myvar) print("\n------------\n" ) print(myvar[1 ]) print("\n------------\n" ) print(myvar[2 ])
运行结果如下
0 1 1 2 2 3 dtype: int64 ------------ 2 ------------ 3
1.2.2 字典方式创建 import pandas as pdsites = {1 : "Google" , 2 : "Runoob" , 3 : "Wiki" } myvar = pd.Series(sites) print(myvar)
运行结果如下
1 Google2 Runoob3 Wikidtype: object
从上可知,字典的 key 变成了索引值。如果我们只需要字典中的一部分数据,只需要指定需要数据的索引即可,如下实例:
import pandas as pdsites = {1 : "Google" , 2 : "Runoob" , 3 : "Wiki" } myvar = pd.Series(sites, index=[1 , 2 ]) print(myvar)
运行结果如下
1 Google2 Runoobdtype: object
注意在上述结果中,第三项数据丢失
1.2.3 设置 Series 名称参数 import pandas as pdsites = {1 : "Google" , 2 : "Runoob" , 3 : "Wiki" } myvar = pd.Series(sites, index=[1 , 2 ], name="RUNOOB-Series-TEST" ) print(myvar)
运行结果如下
1 Google2 RunoobName: RUNOOB-Series-TEST, dtype: object
注意在上述结果中,第三项数据丢失
若修改索引标签,代码如下
import pandas as pdsites = {1 : "Google" , 2 : "Runoob" , 3 : "Wiki" } myvar = pd.Series(sites, index=[1 , 2 , 3 , 4 ], name="RUNOOB-Series-TEST" ) print(myvar)
得到的运行结果如下
1 Google2 Runoob3 Wiki4 NaNName: RUNOOB-Series-TEST, dtype: object
1.3 数据结构 - DataFrame DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)
DataFrame 构造方法如下:
pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
data :一组数据(ndarray、series, map, lists, dict 等类型)。index :索引值,或者可以称为行标签。(==Y轴==)columns :列标签,默认为 RangeIndex (0, 1, 2, …, n) 。(==X轴==)dtype :数据类型。copy :拷贝数据,默认为 False。
1.3.1 基本使用 import pandas as pddata = [['Google' , 10 ], ['Runoob' , 12 ], ['Wiki' , 13 ]] df = pd.DataFrame(data, columns=['Site' , 'Age' ], dtype=float) print(df)
运行结果如下
Site Age 0 Google 10.0 1 Runoob 12.0 2 Wiki 13.0
注意,在创建时列标签必须与数据项保持一致,否则会发生异常 。
对于以下的代码
import pandas as pddata = [['Google' , 10 ], ['Runoob' , 12 ], ['Wiki' , 13 ]] df = pd.DataFrame(data, columns=['Site' , 'Age' , 'name' ], dtype=float) print(df)
运行结果如下
Traceback (most recent call last): File "F:\python\venv\lib\site-packages\pandas\core\internals\construction.py" , line 568 , in _list_to_arrays columns = _validate_or_indexify_columns(content, columns) File "F:\python\venv\lib\site-packages\pandas\core\internals\construction.py" , line 692 , in _validate_or_indexify_columns raise AssertionError( AssertionError: 3 columns passed, passed data had 2 columns The above exception was the direct cause of the following exception: Traceback (most recent call last): File "<input>" , line 1 , in <module> File "C:\Program Files\JetBrains\PyCharm 2021.1.1\plugins\python\helpers\pydev\_pydev_bundle\pydev_umd.py" , line 197 , in runfile pydev_imports.execfile(filename, global_vars, local_vars) File "C:\Program Files\JetBrains\PyCharm 2021.1.1\plugins\python\helpers\pydev\_pydev_imps\_pydev_execfile.py" , line 18 , in execfile exec(compile(contents+"\n" , file, 'exec' ), glob, loc) File "F:/python/PandasDemo.py" , line 5 , in <module> df = pd.DataFrame(data, columns=['Site' , 'Age' , 'name' ], dtype=float) File "F:\python\venv\lib\site-packages\pandas\core\frame.py" , line 570 , in __init__ arrays, columns = to_arrays(data, columns, dtype=dtype) File "F:\python\venv\lib\site-packages\pandas\core\internals\construction.py" , line 528 , in to_arrays return _list_to_arrays(data, columns, coerce_float=coerce_float, dtype=dtype) File "F:\python\venv\lib\site-packages\pandas\core\internals\construction.py" , line 571 , in _list_to_arrays raise ValueError(e) from e ValueError: 3 columns passed, passed data had 2 columns
1.3.2 使用 ndarrays 创建 使用 ndarrays 创建,ndarray 的长度必须相同, 如果传递了 index,则索引的长度应等于数组的长度。如果没有传递索引,则默认情况下,索引将是range(n),其中n是数组长度
对于以下代码
import pandas as pddata = {'Site' : ['Google' , 'Runoob' , 'Wiki' ], 'Age' : [10 , 12 , 13 ]} df = pd.DataFrame(data) print(df)
运行结果如下
Site Age 0 Google 10 1 Runoob 12 2 Wiki 13
注意:这里的每一项的数据的个数必须一致,否则会发生问题
1.3.3 使用字典创建 import pandas as pddata = [{'a' : 1 , 'b' : 2 }, {'a' : 5 , 'b' : 10 , 'c' : 20 }] df = pd.DataFrame(data) print(df)
运行结果如下
a b c 0 1 2 NaN1 5 10 20.0
没有对应的部分数据为 NaN
1.3.4 数据获取 Pandas 可以使用 loc 属性返回指定行的数据,如果没有设置索引,第一行索引为 0 ,第二行索引为 1 ,以此类推:
import pandas as pddata = { "calories" : [420 , 380 , 390 ], "duration" : [50 , 40 , 45 ] } df = pd.DataFrame(data) print(df) print("\n------------\n" ) print(df.loc[0 ]) print("\n------------\n" ) print(df.loc[1 ])
运行结果如下
calories duration 0 420 50 1 380 40 2 390 45 ------------ calories 420 duration 50 Name: 0 , dtype: int64 ------------ calories 380 duration 40 Name: 1 , dtype: int64
注意: 返回结果其实就是一个 Pandas Series 数据。
也可以返回多行数据,使用 [[ … ]] 格式,… 为各行的索引,以逗号隔开:
import pandas as pddata = { "calories" : [420 , 380 , 390 ], "duration" : [50 , 40 , 45 ] } df = pd.DataFrame(data) print(df.loc[[0 , 1 ]])
运行结果为
calories duration 0 420 50 1 380 40
指定索引值
import pandas as pddata = { "calories" : [420 , 380 , 390 ], "duration" : [50 , 40 , 45 ] } df = pd.DataFrame(data, index=["day1" , "day2" , "day3" ]) print(df) print("\n------------\n" ) print(df.loc["day2" ])
运行结果为
calories duration day1 420 50 day2 380 40 day3 390 45 ------------ calories 380 duration 40 Name: day2, dtype: int64
1.4 CSV文件数据 CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)
1.4.1 基本使用 import pandas as pddf = pd.read_csv('demo.csv' ) print(df.to_string())
to_string() 用于返回 DataFrame 类型的数据,如果不使用该函数,则输出结果为数据的前面 5 行和末尾 5 行,直接部分以 … 代替
对于以下代码
import pandas as pddf = pd.read_csv('demo.csv' ) print("\n" ) print(df)
输出结果如下
5.1 3.5 1.4 0.2 Iris-setosa 0 4.9 3.0 1.4 0.2 Iris-setosa1 4.7 3.2 1.3 0.2 Iris-setosa2 4.6 3.1 1.5 0.2 Iris-setosa3 5.0 3.6 1.4 0.2 Iris-setosa4 5.4 3.9 1.7 0.4 Iris-setosa.. ... ... ... ... ... 144 6.7 3.0 5.2 2.3 Iris-virginica145 6.3 2.5 5.0 1.9 Iris-virginica146 6.5 3.0 5.2 2.0 Iris-virginica147 6.2 3.4 5.4 2.3 Iris-virginica148 5.9 3.0 5.1 1.8 Iris-virginica
注意CSV文件中的第一行这里视为标题了。
若想忽略标题,可以使用以下方式读取
data = pd.read_csv(path, header=None )
1.4.2 将数据保存为CSV文件 import pandas as pdnme = ["Google" , "Runoob" , "Taobao" , "Wiki" ] st = ["www.google.com" , "www.runoob.com" , "www.taobao.com" , "www.wikipedia.org" ] ag = [90 , 40 , 80 , 98 ] dict = {'name' : nme, 'site' : st, 'age' : ag} df = pd.DataFrame(dict) df.to_csv('site.csv' )
运行上述代码,会得到一个csv文件,文件内容如下
,name,site,age 0 ,Google,www.google.com,90 1 ,Runoob,www.runoob.com,40 2 ,Taobao,www.taobao.com,80 3 ,Wiki,www.wikipedia.org,98
1.4.3 数据处理 head( *n* ) 方法用于读取前面的 n 行,如果不填参数 n ,默认返回 5 行
import pandas as pddf = pd.read_csv('demo.csv' ) print(df.head())
运行结果如下
5.1 3.5 1.4 0.2 Iris-setosa 0 4.9 3.0 1.4 0.2 Iris-setosa1 4.7 3.2 1.3 0.2 Iris-setosa2 4.6 3.1 1.5 0.2 Iris-setosa3 5.0 3.6 1.4 0.2 Iris-setosa4 5.4 3.9 1.7 0.4 Iris-setosa
tail()
tail( *n* ) 方法用于读取尾部的 n 行,如果不填参数 n ,默认返回 5 行,空行各个字段的值返回 NaN 。
import pandas as pddf = pd.read_csv('demo.csv' ) print(df.tail(3 ))
运行代码,结果为
5.1 3.5 1.4 0.2 Iris-setosa 146 6.5 3.0 5.2 2.0 Iris-virginica147 6.2 3.4 5.4 2.3 Iris-virginica148 5.9 3.0 5.1 1.8 Iris-virginica
info()
info() 方法返回表格的一些基本信息:
import pandas as pddf = pd.read_csv('demo.csv' ) print(df.info())
结果如下
<class 'pandas .core .frame .DataFrame '> RangeIndex :149 entries, 0 to 148 Data columns (total 5 columns): --- ------ -------------- ----- 0 5.1 149 non-null float64 1 3.5 149 non-null float64 2 1.4 149 non-null float64 3 0.2 149 non-null float64 4 Iris-setosa 149 non-null object dtypes: float64(4 ), object(1 ) memory usage: 5.9 + KB None
1.5 JSON数据 1.5.1 基本使用 import pandas as pddata = [ { "id" : "A001" , "name" : "菜鸟教程" , "url" : "www.runoob.com" , "likes" : 61 }, { "id" : "A002" , "name" : "Google" , "url" : "www.google.com" , "likes" : 124 }, { "id" : "A003" , "name" : "淘宝" , "url" : "www.taobao.com" , "likes" : 45 } ] df = pd.DataFrame(data) print(df)
运行结果如下
id name url likes 0 A001 菜鸟教程 www.runoob.com 61 1 A002 Google www.google.com 124 2 A003 淘宝 www.taobao.com 45
1.5.2 从 URL 中读取 JSON 数据 import pandas as pdURL = 'https://static.runoob.com/download/sites.json' df = pd.read_json(URL) print(df)
运行结果如下
id name url likes 0 A001 菜鸟教程 www.runoob.com 61 1 A002 Google www.google.com 124 2 A003 淘宝 www.taobao.com 45
二 matplotlib.pyplot Matplotlib 是 Python 的绘图库。 它可与 NumPy 一起使用,提供了一种有效的 MatLab 开源替代方案。 它也可以和图形工具包一起使用,如 PyQt 和 wxPython
pip3 安装:
pip3 install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
使用pyplot
import matplotlib.pyplot as plt
也可以使用下面的方法使用
from matplotlib import pyplot as plt
2.1 基础使用 2.1.1 简单使用 第一个简单的应用
import numpy as npfrom matplotlib import pyplot as pltx = np.arange(1 , 11 ) y = 2 * x + 5 plt.title("Matplotlib demo" ) plt.xlabel("x axis caption" ) plt.ylabel("y axis caption" ) plt.plot(x, y) plt.show()
运行之后,可以得到下面的一副图片
2.1.2 中文支持 对于2.1.1中的实例,在默认情况下是不支持中文的,如设置了中文,则会出现乱码,因此需要通过设置以支持汉字。
import numpy as npfrom matplotlib import pyplot as pltimport matplotlib as mplx = np.arange(1 , 11 ) y = 2 * x + 5 mpl.rcParams["font.sans-serif" ] = ["simHei" ] mpl.rcParams["axes.unicode_minus" ] = False plt.title("标题" ) plt.xlabel("X轴" ) plt.ylabel("Y轴" ) plt.plot(x, y) plt.show()
运行代码,得到的结果如下
2.2 图形绘制 2.2.1 简单图形 import matplotlib.pyplot as pltimport matplotlib as mplinput_values = [1 , 2 , 3 , 4 , 5 ] squares = [1 , 4 , 9 , 16 , 25 ] mpl.rcParams["font.sans-serif" ] = ["simHei" ] mpl.rcParams["axes.unicode_minus" ] = False plt.plot(input_values, squares, linewidth=5 ) plt.title("简单图形绘制" , fontsize=30 ) plt.xlabel("X轴" , fontsize=8 ) plt.ylabel("Y轴 " , fontsize=14 ) plt.tick_params(axis='both' , labelsize=14 ) plt.show()
结果如下
2.2.2 绘制点 import matplotlib.pyplot as pltimport matplotlib as mplplt.scatter(2 , 4 ) plt.scatter(3 , 5 , s=200 ) plt.show()
结果为
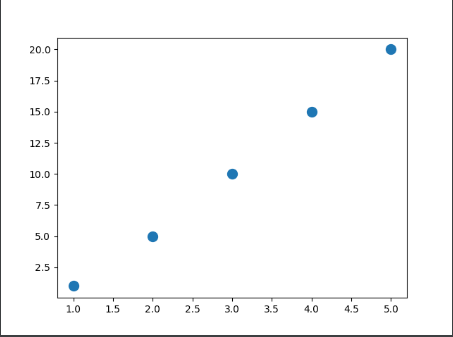
2.2.3 一系列的点 import matplotlib.pyplot as pltimport matplotlib as mplx_values = [1 , 2 , 3 , 4 , 5 ] y_values = [1 , 5 , 10 , 15 , 20 ] plt.scatter(x_values, y_values, s=100 ) plt.show()
结果为
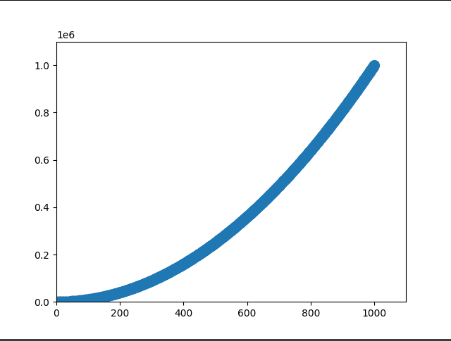
2.2.4 自动计算数据 import matplotlib.pyplot as pltimport matplotlib as mplx_values = list(range(1 , 1001 )) y_values = [x ** 2 for x in x_values] plt.scatter(x_values, y_values, s=100 ) plt.axis([0 , 1100 , 0 , 1100000 ]) plt.show()
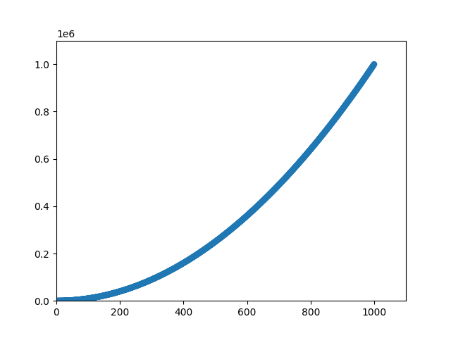
2.2.5 删除数据点的轮廓 import matplotlib.pyplot as pltimport matplotlib as mplx_values = list(range(1 , 1001 )) y_values = [x ** 2 for x in x_values] plt.scatter(x_values, y_values, edgecolor='none' , s=40 ) plt.axis([0 , 1100 , 0 , 1100000 ]) plt.show()
2.2.6 自定义颜色 import matplotlib.pyplot as pltimport matplotlib as mplx_values = list(range(1 , 1001 )) y_values = [x ** 2 for x in x_values] plt.scatter(x_values, y_values, c='green' , edgecolor='none' , s=40 ) plt.axis([0 , 1100 , 0 , 1100000 ]) plt.show()
2.2.7 使用颜色映射 将c设置成一个y值列表,并使用参数cmap告诉pyplot使用那个颜色映射,这些代码将y值较小的点显示为浅蓝色,将y值较大的点显示为深蓝色
import matplotlib.pyplot as pltimport matplotlib as mplx_values = list(range(1 , 1001 )) y_values = [x ** 2 for x in x_values] plt.scatter(x_values, y_values, c=y_values, cmap=plt.cm.Blues, edgecolor='none' , s=40 ) plt.axis([0 , 1100 , 0 , 1100000 ]) plt.show()
2.2.8 自动保存图表 import matplotlib.pyplot as pltimport matplotlib as mplx_values = list(range(1 , 1001 )) y_values = [x ** 2 for x in x_values] plt.scatter(x_values, y_values, c=y_values, cmap=plt.cm.Blues, edgecolor='none' , s=40 ) plt.axis([0 , 1100 , 0 , 1100000 ]) plt.savefig('demo.png' , bbox_inches='tight' )
2.2.9 绘制条形图 import matplotlib.pyplot as pltimport matplotlib as mplmpl.rcParams["font.sans-serif" ] = ["simHei" ] mpl.rcParams["axes.unicode_minus" ] = False x = [5 , 8 , 10 ] y = [12 , 16 , 6 ] x2 = [6 , 9 , 11 ] y2 = [6 , 15 , 7 ] plt.bar(x, y, align='center' ) plt.bar(x2, y2, color='g' , align='center' ) plt.title('条形图' ) plt.ylabel('Y轴' ) plt.xlabel('X轴' ) plt.show()
2.2.10 绘制直方图 Matplotlib 可以将直方图的数字表示转换为图形。 pyplot 子模块的 plt() 函数将包含数据和 bin 数组的数组作为参数,并转换为直方图
import matplotlib.pyplot as pltimport matplotlib as mplimport numpy as npmpl.rcParams["font.sans-serif" ] = ["simHei" ] mpl.rcParams["axes.unicode_minus" ] = False a = np.array([22 , 87 , 5 , 43 , 56 , 73 , 55 , 54 , 11 , 20 , 51 , 5 , 79 , 31 , 27 ]) plt.hist(a, bins=[0 , 20 , 40 , 60 , 80 , 100 ]) plt.title("直方图" ) plt.show()