/** * The maximum capacity, used if a higher value is implicitly specified * by either of the constructors with arguments. * MUST be a power of two <= 1<<30. */ staticfinalint MAXIMUM_CAPACITY = 1 << 30;
/** * The load factor used when none specified in constructor. */ staticfinalfloat DEFAULT_LOAD_FACTOR = 0.75f; /** * 该表在首次使用时初始化,并根据需要调整大小。 分配时,长度始终是2的幂。 * (在某些操作中,我们还允许长度为零,以 * 允许使用当前不需要的引导机制。) */ transient Node<K, V>[] table;
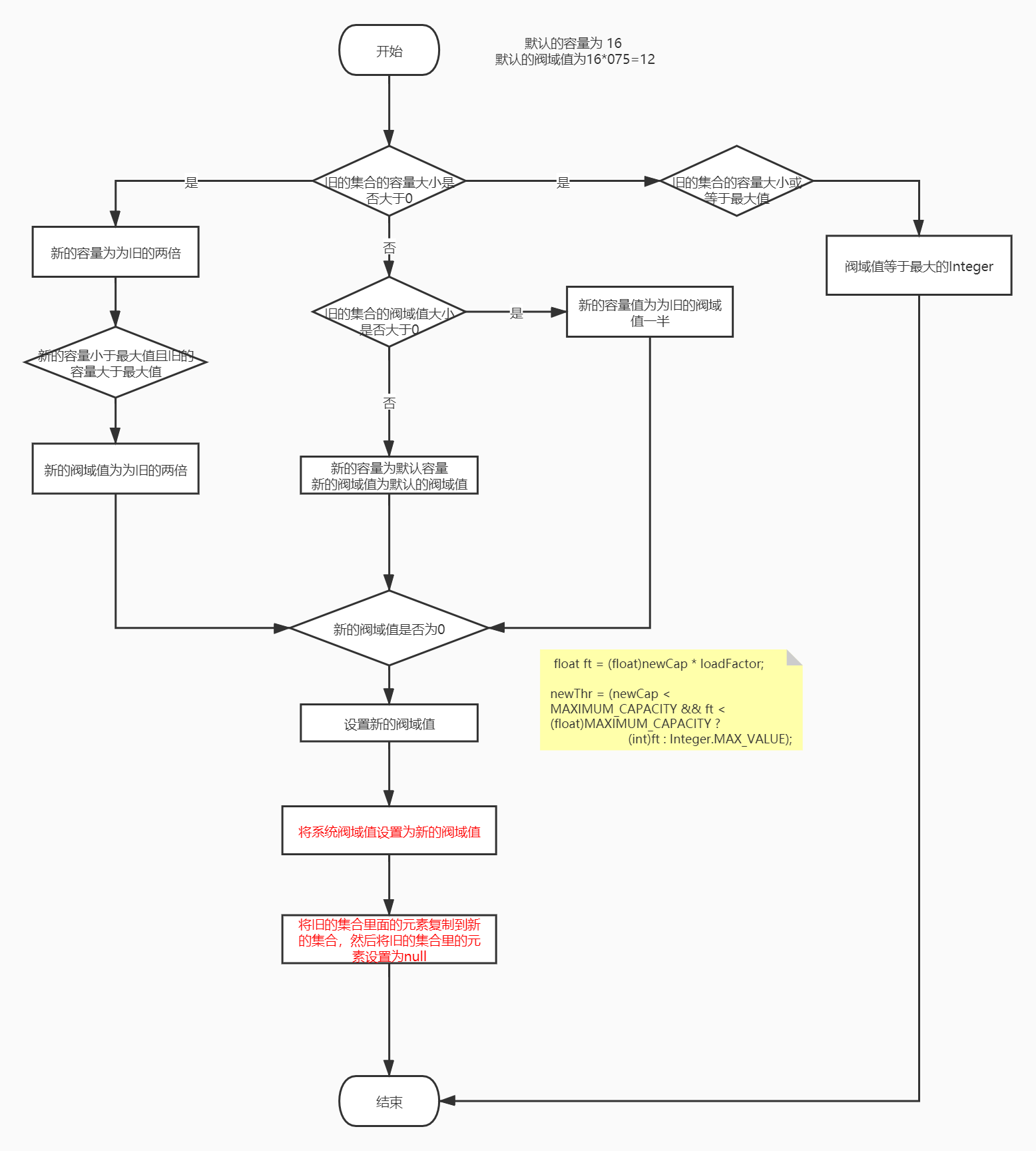
/** * 对该HashMap进行结构修改的次数结构修改是指更改HashMap中的 * 映射次数或以其他方式修改其内部结构(例如,重新哈希)的修改。 * 此字段用于使HashMap的Collection-view上的迭代器快速失败。 * (请参见ConcurrentModificationException)。 */ transientint modCount; /** * The next size value at which to resize (capacity * load factor). * 阀域值 * @serial */ // (The javadoc description is true upon serialization. // Additionally, if the table array has not been allocated, this // field holds the initial array capacity, or zero signifying // DEFAULT_INITIAL_CAPACITY.) int threshold;
/** * Associates the specified value with the specified key in this map. * If the map previously contained a mapping for the key, the old * value is replaced. * * @param key key with which the specified value is to be associated * @param value value to be associated with the specified key * @return the previous value associated with <tt>key</tt>, or * <tt>null</tt> if there was no mapping for <tt>key</tt>. * (A <tt>null</tt> return can also indicate that the map * previously associated <tt>null</tt> with <tt>key</tt>.) */ public V put(K key, V value){ return putVal(hash(key), key, value, false, true); }
这里其实调用的是putVal方法,其具体参见如下
/** * Implements Map.put and related methods * * @param hash hash for key * @param key the key * @param value the value to put * @param onlyIfAbsent if true, don't change existing value * @param evict if false, the table is in creation mode. * @return previous value, or null if none */ final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict){ Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) //执行一次,第一次才会执行 ,这里会触发 【扩容】 n = (tab = resize()).length; // 注意 tab[i = (n - 1) & hash] if ((p = tab[i = (n - 1) & hash]) == null) //如果key已经存在就不会进入 tab[i] = newNode(hash, key, value, null); else { // key 已经存在才会进入 Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; elseif (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st //除非表太小,否则用给定的哈希替换索引中bin处bin中的所有链接节点,在这种情况下,将调整大小。 treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); // 注意这里流程中断 return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); returnnull; }
/** * Returns the value to which the specified key is mapped, * or {@code null} if this map contains no mapping for the key. * * <p>More formally, if this map contains a mapping from a key * {@code k} to a value {@code v} such that {@code (key==null ? k==null : * key.equals(k))}, then this method returns {@code v}; otherwise * it returns {@code null}. (There can be at most one such mapping.) * * <p>A return value of {@code null} does not <i>necessarily</i> * indicate that the map contains no mapping for the key; it's also * possible that the map explicitly maps the key to {@code null}. * The {@link #containsKey containsKey} operation may be used to * distinguish these two cases. * * @see #put(Object, Object) */ public V get(Object key){ Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; }
具体的getNode的定义如下
/** * Implements Map.get and related methods * * @param hash hash for key * @param key the key * @return the node, or null if none */ final Node<K,V> getNode(int hash, Object key){ Node<K,V>[] tab; Node<K,V> first, e; int n; K k; if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { //第一个元素的key 与给定的key是否相等 if (first.hash == hash && // always check first node ((k = first.key) == key || (key != null && key.equals(k)))) return first; if ((e = first.next) != null) { if (first instanceof TreeNode) return ((TreeNode<K,V>)first).getTreeNode(hash, key); do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } returnnull; }
publicfinal V setValue(V newValue){ V oldValue = value; value = newValue; return oldValue; }
publicfinalbooleanequals(Object o){ if (o == this) returntrue; if (o instanceof Map.Entry) { Map.Entry<?,?> e = (Map.Entry<?,?>)o; if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) returntrue; } returnfalse; } }


.jpg)