package org.example;
import com.yishuifengxiao.common.tool.random.IdWorker;
import lombok.extern.slf4j.Slf4j;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.jdbc.core.BatchPreparedStatementSetter;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.test.context.junit4.SpringRunner;
import org.springframework.util.StopWatch;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.time.LocalDateTime;
import java.util.Arrays;
import java.util.List;
import java.util.Objects;
import java.util.UUID;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
@SpringBootTest
@RunWith(SpringRunner.class)
@Slf4j
public class DataTest {
@Autowired
private JdbcTemplate jdbcTemplate;
@Test
public void test() {
List<Integer> list = Arrays.asList(10, 50, 100, 200, 300, 400, 500, 1000, 2000, 3000, 4000, 5000, 10000,
20000, 30000, 40000, 50000, 100000, 200000, 300000, 400000, 500000, 1000000, 2000000, 3000000,
4000000, 5000000, 10000000);
list.forEach(length -> {
insertIdIncrement(length);
insertIdInc(length);
insertIdSnow(length);
insertIdUuid(length);
});
System.out.println("-------> 运行完成");
}
public void insertIdIncrement(int length) {
jdbcTemplate.execute("truncate table id_increment ");
StopWatch stopWatch = new StopWatch("【自增ID】插入性能测试:数量-" + length);
stopWatch.start("【自增ID】[准备数据]:数量-" + length);
List<IdIncrement> list =
IntStream.range(0, length).mapToObj(v -> new IdIncrement(System.currentTimeMillis() + "",
System.currentTimeMillis() + "", LocalDateTime.now())).collect(Collectors.toList());
stopWatch.stop();
stopWatch.start("【自增ID】[数据插入]:数量-" + length);
String sql = "INSERT INTO `id_increment` ( `name`, `create_time`, `pwd`) VALUES ( ?, " + "?, ?) ";
jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
ps.setObject(1, list.get(i).getName());
ps.setObject(2, list.get(i).getCreateTime());
ps.setObject(3, list.get(i).getPwd());
if (Objects.equals(i, list.size())) {
ps.executeLargeBatch();
ps.clearBatch();
} else {
if (i % 500 == 0) {
ps.executeLargeBatch();
ps.clearBatch();
}
}
}
@Override
public int getBatchSize() {
return list.size();
}
});
stopWatch.stop();
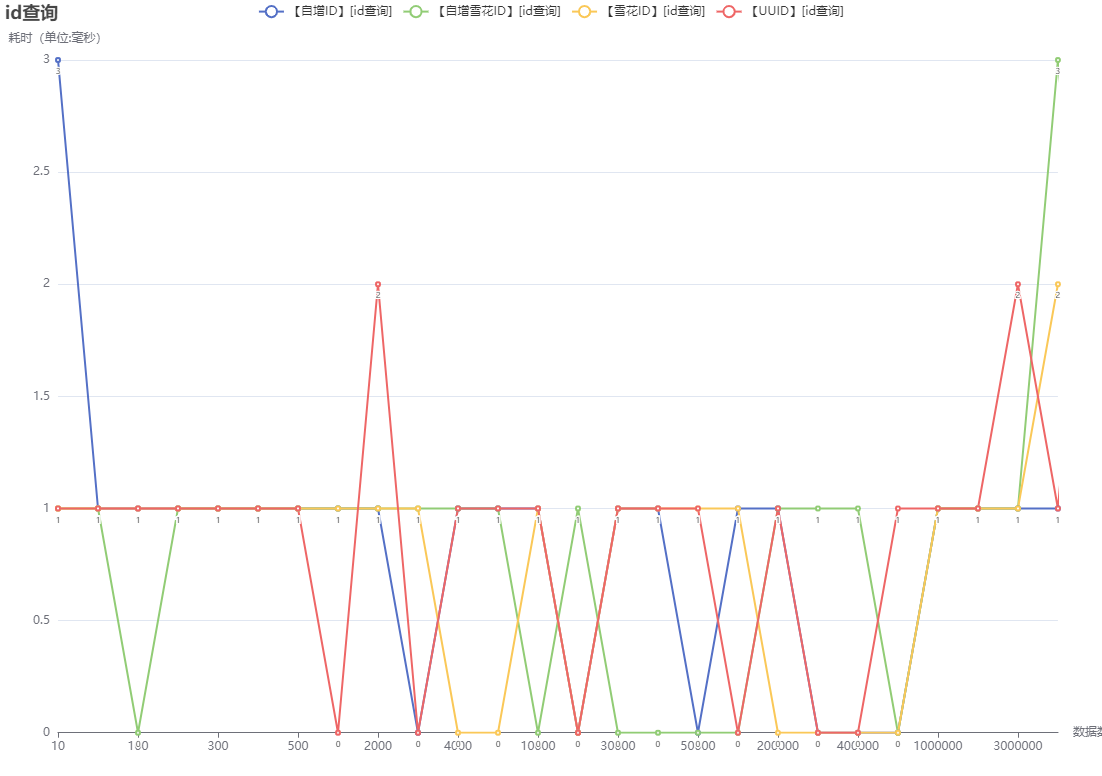
stopWatch.start("【自增ID】[id查询]:数量-" + length);
jdbcTemplate.queryForList("select * from id_increment where id = " + 10);
stopWatch.stop();
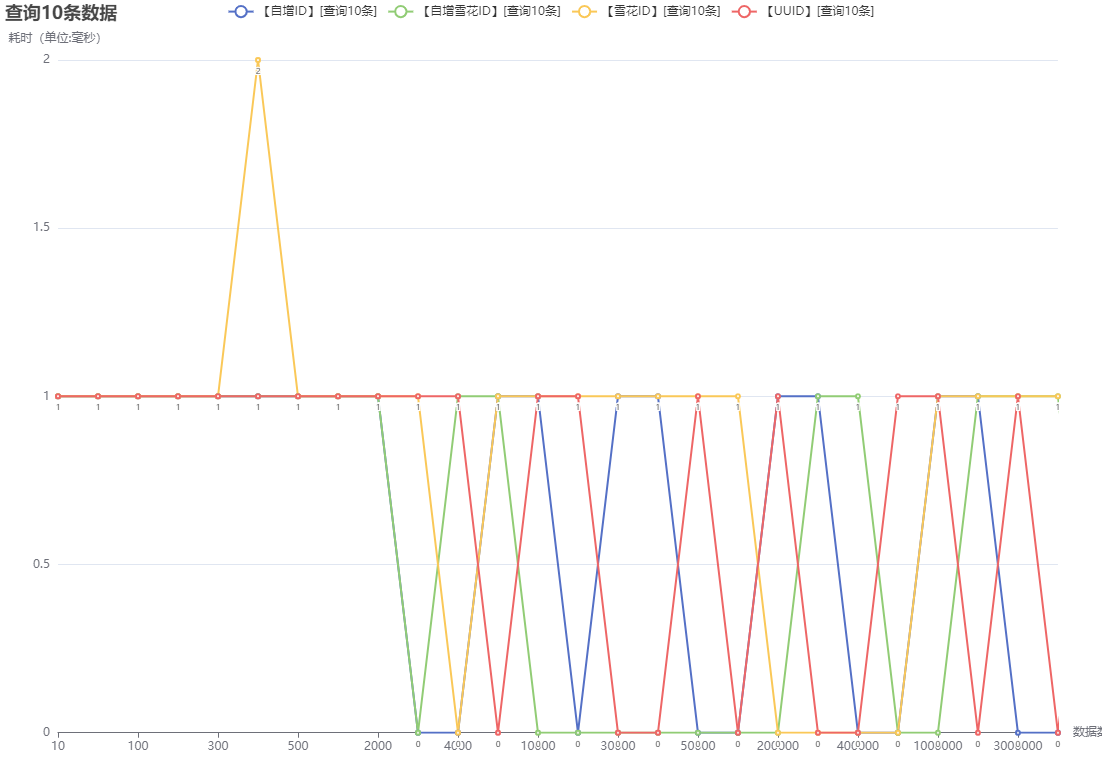
stopWatch.start("【自增ID】[查询10条]:数量-" + length);
jdbcTemplate.queryForList("select * from id_increment limit 10");
stopWatch.stop();
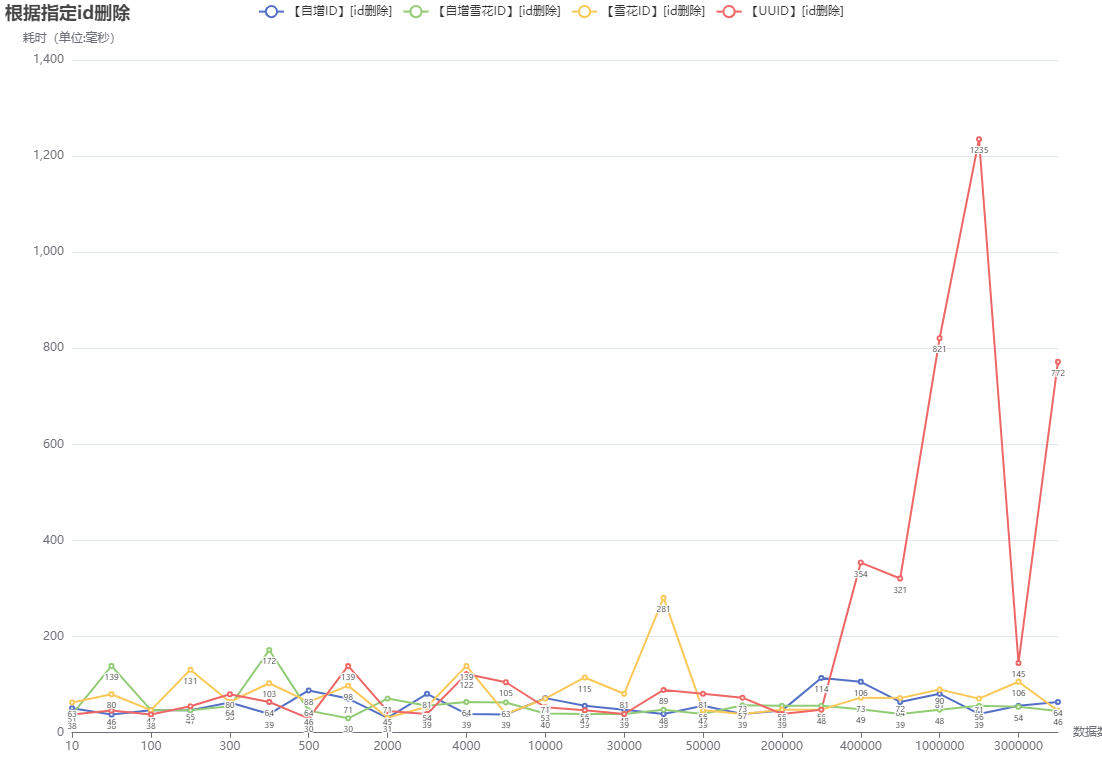
stopWatch.start("【自增ID】[id删除]:数量-" + length);
jdbcTemplate.execute("delete from id_increment where id = " + 10);
stopWatch.stop();
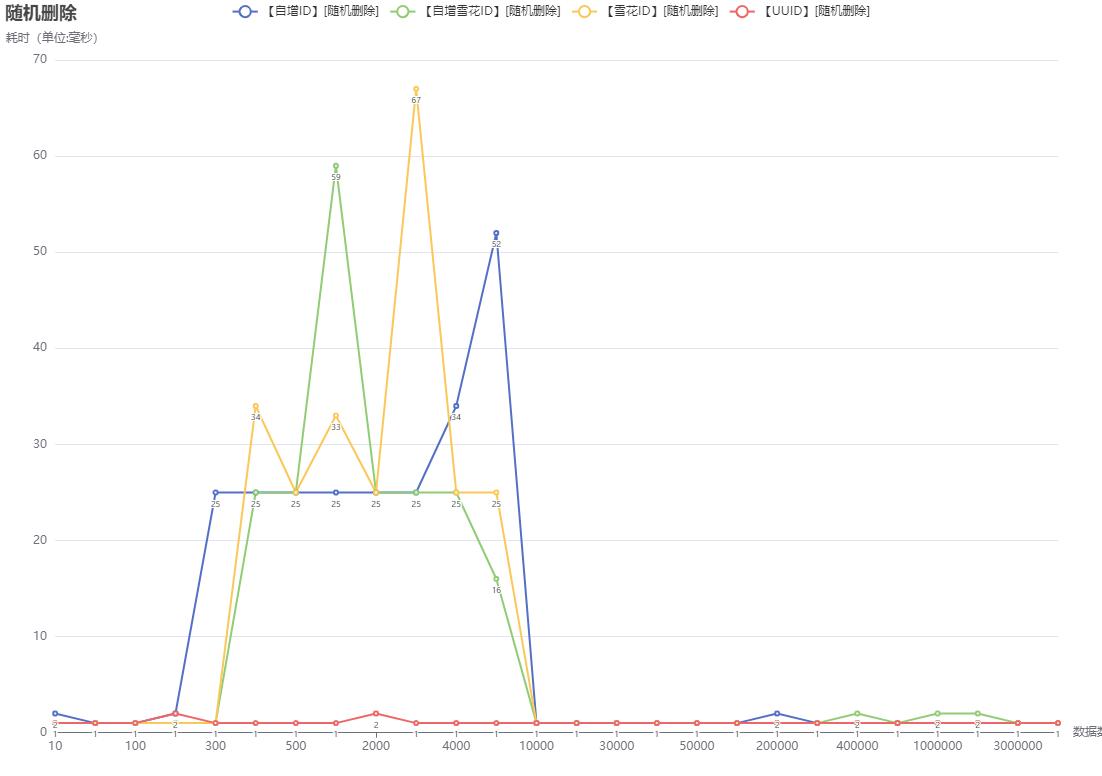
stopWatch.start("【自增ID】[随机删除]:数量-" + length);
jdbcTemplate.execute("delete from id_increment where id = " + System.currentTimeMillis());
stopWatch.stop();
log.warn("【自增ID】耗时统计信息为\r\n {}", stopWatch.prettyPrint(TimeUnit.MILLISECONDS));
}
public void insertIdInc(int length) {
jdbcTemplate.execute("truncate table id_inc ");
StopWatch stopWatch = new StopWatch("【自增雪花ID】插入性能测试:数量-" + length);
stopWatch.start("【自增雪花ID】[准备数据]:数量-" + length);
List<IdIncrement> list = IntStream.range(0, length).mapToObj(v -> new IdIncrement(IdWorker.snowflakeId(),
System.currentTimeMillis() + "", System.currentTimeMillis() + "", LocalDateTime.now())).collect(Collectors.toList());
Long id = list.get(list.size() - 1).getId();
stopWatch.stop();
stopWatch.start("【自增雪花ID】[数据插入]:数量-" + length);
String sql = "INSERT INTO `id_inc` ( `id`,`name`, `create_time`, `pwd`) VALUES ( ?,?, " + "?, ?) ";
jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
ps.setObject(1, list.get(i).getId());
ps.setObject(2, list.get(i).getName());
ps.setObject(3, list.get(i).getCreateTime());
ps.setObject(4, list.get(i).getPwd());
if (Objects.equals(i, list.size())) {
ps.executeLargeBatch();
ps.clearBatch();
} else {
if (i % 500 == 0) {
ps.executeLargeBatch();
ps.clearBatch();
}
}
}
@Override
public int getBatchSize() {
return list.size();
}
});
stopWatch.stop();
stopWatch.start("【自增雪花ID】[id查询]:数量-" + length);
jdbcTemplate.queryForList("select * from id_inc where id = " + id);
stopWatch.stop();
stopWatch.start("【自增雪花ID】[查询10条]:数量-" + length);
jdbcTemplate.queryForList("select * from id_inc limit 10");
stopWatch.stop();
stopWatch.start("【自增雪花ID】[id删除]:数量-" + length);
jdbcTemplate.execute("delete from id_inc where id = " + id);
stopWatch.stop();
stopWatch.start("【自增雪花ID】[随机删除]:数量-" + length);
jdbcTemplate.execute("delete from id_inc where id = " + System.currentTimeMillis());
stopWatch.stop();
log.warn("【自增雪花ID】耗时统计信息为\r\n {}", stopWatch.prettyPrint(TimeUnit.MILLISECONDS));
}
public void insertIdSnow(int length) {
jdbcTemplate.execute("truncate table id_snow ");
StopWatch stopWatch = new StopWatch("【雪花ID】插入性能测试:数量-" + length);
stopWatch.start("【雪花ID】[准备数据]:数量-" + length);
List<IdSnow> list = IntStream.range(0, length).mapToObj(v -> new IdSnow(IdWorker.snowflakeId(),
System.currentTimeMillis() + "", System.currentTimeMillis() + "", LocalDateTime.now())).collect(Collectors.toList());
Long id = list.get(list.size() - 1).getId();
stopWatch.stop();
stopWatch.start("【雪花ID】[数据插入]:数量-" + length);
String sql = "INSERT INTO `id_snow` (`id`, `name`, `create_time`, `pwd`) VALUES (?, ?, " + "?, ?) ";
jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
ps.setObject(1, list.get(i).getId());
ps.setObject(2, list.get(i).getName());
ps.setObject(3, list.get(i).getCreateTime());
ps.setObject(4, list.get(i).getPwd());
if (Objects.equals(i, list.size())) {
ps.executeLargeBatch();
ps.clearBatch();
} else {
if (i % 500 == 0) {
ps.executeLargeBatch();
ps.clearBatch();
}
}
}
@Override
public int getBatchSize() {
return list.size();
}
});
stopWatch.stop();
stopWatch.start("【雪花ID】[id查询]:数量-" + length);
jdbcTemplate.queryForList("select * from id_snow where id = " + id);
stopWatch.stop();
stopWatch.start("【雪花ID】[查询10条]:数量-" + length);
jdbcTemplate.queryForList("select * from id_snow limit 10");
stopWatch.stop();
stopWatch.start("【雪花ID】[id删除]:数量-" + length);
jdbcTemplate.execute("delete from id_snow where id = " + id);
stopWatch.stop();
stopWatch.start("【雪花ID】[随机删除]:数量-" + length);
jdbcTemplate.execute("delete from id_snow where id = " + System.currentTimeMillis());
stopWatch.stop();
log.warn("【雪花ID】耗时统计信息为\r\n {}", stopWatch.prettyPrint(TimeUnit.MILLISECONDS));
}
public void insertIdUuid(int length) {
jdbcTemplate.execute("truncate table id_uuid ");
StopWatch stopWatch = new StopWatch("【UUID】插入性能测试:数量-" + length);
stopWatch.start("【UUID】[准备数据]:数量-" + length);
List<IdUuid> list = IntStream.range(0, length).mapToObj(v -> new IdUuid(UUID.randomUUID().toString(),
System.currentTimeMillis() + "", System.currentTimeMillis() + "", LocalDateTime.now())).collect(Collectors.toList());
String id = list.get(list.size() - 1).getId();
stopWatch.stop();
stopWatch.start("【UUID】[数据插入]");
String sql = "INSERT INTO `id_uuid` (`id`, `name`, `create_time`, `pwd`) VALUES (?, ?, " + "?, ?) ";
jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
ps.setObject(1, list.get(i).getId());
ps.setObject(2, list.get(i).getName());
ps.setObject(3, list.get(i).getCreateTime());
ps.setObject(4, list.get(i).getPwd());
if (Objects.equals(i, list.size())) {
ps.executeLargeBatch();
ps.clearBatch();
} else {
if (i % 500 == 0) {
ps.executeLargeBatch();
ps.clearBatch();
}
}
}
@Override
public int getBatchSize() {
return list.size();
}
});
stopWatch.stop();
stopWatch.start("【UUID】[id查询]:数量-" + length);
jdbcTemplate.queryForList("select * from id_uuid where id = '" + id + "'");
stopWatch.stop();
stopWatch.start("【UUID】[查询10条]:数量-" + length);
jdbcTemplate.queryForList("select * from id_uuid limit 10");
stopWatch.stop();
stopWatch.start("【UUID】[id删除]:数量-" + length);
jdbcTemplate.execute("delete from id_uuid where id = '" + id + "'");
stopWatch.stop();
stopWatch.start("【UUID】[随机删除]:数量-" + length);
jdbcTemplate.execute("delete from id_uuid where id = '" + UUID.randomUUID().toString() + "'");
stopWatch.stop();
log.warn("【UUID】耗时统计信息为\r\n {}", stopWatch.prettyPrint(TimeUnit.MILLISECONDS));
}
}
|
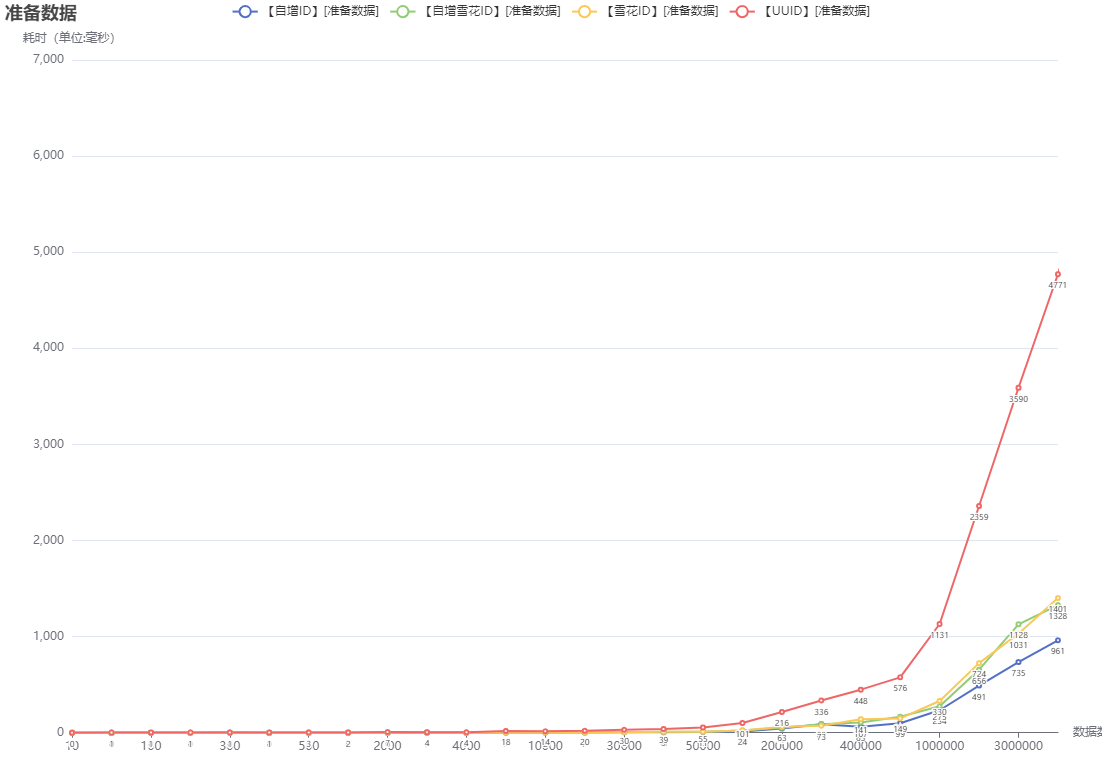
-170607372229711.png)
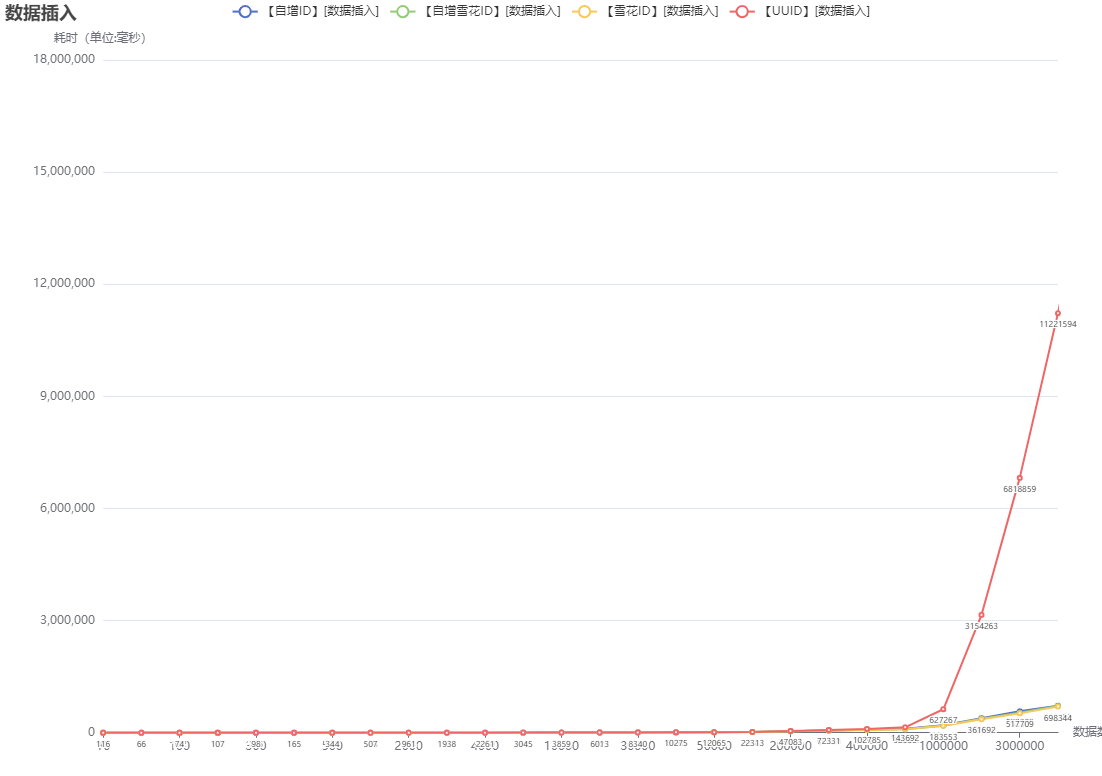

-170607329125010.png)